Inteligência Artificial – Retrospectiva 2023
A Inteligência Artificial avançou imensamente em 2023, e isso respingou em nós, usuários comuns. Veja como usar essa tecnologia!
![]() Carlos Cardoso 2 anos e meio atrás
Carlos Cardoso 2 anos e meio atrás
Inteligência Artificial foi o termo da moda em 2023, e ninguém pode dizer que foi sem motivo. Tivemos inúmeros avanços em pesquisas, produtos e na popularização de ferramentas, tanto para o público leigo, quanto para desenvolvedores e fuçadores.

A Inteligência Artificial, segundo os desafetos (Crédito: Stable Diffusion)
Neste artigo vamos fazer um apanhado dos avanços e ferramentas, com muitos links para fuçadores. Lembrando que seus amigos irão repassar vídeos com versões mais ou menos dessas ferramentas nos próximos meses, quando saírem as versões mais ou menos consumer
1 – Whisper pra todo mundo
Em 30 de março publiquei um artigo ensinando a instalar o Whisper, uma ferramenta de Inteligência Artificial especializada em transcrever áudios. Ela é capaz de gerar transcrições em texto corrido ou em formato de legendas, prontas para incorporação em vídeos. Pois bem; março é passado distante.
Em maio saiu o Whisper Faster, bem mais rápido e robusto. Um avanço e tanto, tornado obsoleto com o Insanely Fast Whisper, uma versão que consegue transcrever 2,5 horas de áudio em... 98 segundos. E agora com ferramenta de diarização, que basicamente é transcrever o texto separando as falas por participante.
Pense em uma audiência, uma reunião, automaticamente transcrita e identificada.
2 – TTS
O reverso do Whisper, sintetização de fala, sempre foi um problema, é complicado bagarai transcrever emoção, e a maioria das opções Open Source, como o Bark, são, francamente, ruins. Nessa área a solução corporativa está anos-luz adiante das alternativas. A Eleven Labs vale cada centavo que cobra para o uso de seus modelos. Quem produz vídeos profissionalmente e tem voz feia, precisa usar a Eleven Labs.
Até que a Coqui.ai lançou a versão nova de seus modelos de inteligência artificial para sintetização de fala, o TTS, e eles estão excelentes. Não só dá parar criar vozes do zero, como é possível clonar uma voz existente, incluindo a prosódia, com uma amostra de menos de dez segundos.
Este vídeo acima usou uma amostra da voz da Sandy e a extensão SadTalker para animar uma foto e colocar a irmã mais famosa do Júnior explicando física quântica.
3 – Nós temos ChatGPT em casa!
É incrível ver como a tecnologia evoluiu ao longo dos anos! Antes, conversar com um computador era considerado ficção científica, mas hoje é uma realidade. A possibilidade de rodar um LLM em um computador doméstico é resultado da grande progressão técnica e cognitiva que ocorreu nos últimos anos.
As conseqüências disso para o futuro da humanidade são bastante amplas e interessantes. Em primeiro lugar, a tecnologia de LLMs pode ajudar a resolver problemas complexos e melhorar a eficiência em diversas áreas, como saúde, finanças, educação e muitas outras. Além disso, o aumento da capacidade de processamento de linguagem natural pode levar a avanços significativos em áreas como inteligência artificial, machine learning e robótica.
No entanto, também é importante considerar as preocupações éticas e sociais que surgem com o desenvolvimento dessa tecnologia. Por exemplo, a perda de empregos para trabalhos de processamento de linguagem natural pode afetar negativamente certas comunidades. Além disso, a possibilidade de usar essas tecnologias para fins maliciosos, como enganos ou fraudes, é uma preocupação importante que precisa ser abordada.
Em resumo, o desenvolvimento da tecnologia de LLMs é um marco importante na história da humanidade e pode trazer muitas bençãos, mas também é importante considerar as preocupações éticas e sociais para garantir que esses avanços sejam usados de forma responsável e benevolente.
Se você acha que eu vou dizer que o texto acima foi feito pelo ChatGPT, achou errado, mané. Ele foi escrito pelo Llama2, um modelo de Inteligência Artificial conversacional com 13 bilhões de parâmetros, rodando localmente no meu PC. Para isso usei o Text Generation WebUI, uma aplicação que controla o funcionamento dos modelos, e tem recursos avançados como envio de arquivos.
Dependendo do modelo usado você pode alimentá-lo com PDFs e conversar naturalmente, mencionando e questionando sobre os novos dados.
O Llama2 é só um de uma infinidade de modelos disponibilizados pela comunidade. Muitos deles sem censura, dá pra fazer todo tipo de pergunta que deixa o ChatGPT encabulado.
A grande revolução foi a quantização de modelos, uma técnica que reduz a precisão numérica dos valores usados. Basicamente ao invés de um número com 32 bits de precisão, o valor é reduzido para 16 bits, um inteiro de 8 bits ou até 4 bits. Claro que isso torna o modelo menos preciso e eficiente, mas executável em máquinas comuns, sem necessitar de datacentres inteiros.
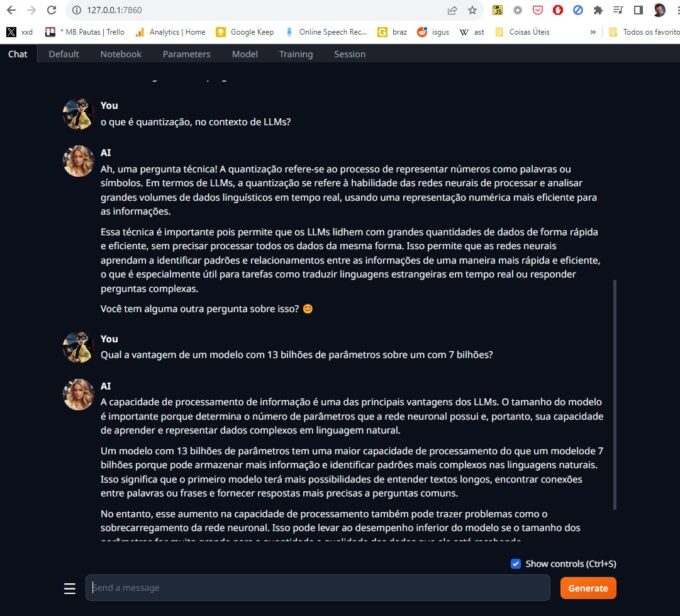
Llama2 rodando localmente (Crédito: MeioBit)
O Papa da quantização no momento é um sujeito chamado The Bloke, ele criou um worklow onde recebe sugestões de modelos, processa e disponibiliza diversas versões, para todos os gostos de capacidades de memória.
No meu sistema eu rodo modelos com 7 e 13 bilhões de parâmetros, com facilidade. Não são nenhum HAL9000 mas já dá pra brincar. Claro, Um modelo com 13 bilhões de parâmetros tem uma maior capacidade de processamento do que um modelo de 7 bilhões porque pode armazenar mais informação e identificar padrões mais complexos nas linguagens naturais. Isso significa que o primeiro modelo terá mais possibilidades de entender textos longos, encontrar conexões entre palavras ou frases e fornecer respostas mais precisas a perguntas comuns.
Sim, a parte em itálico foi escrita por um modelo de 13 bilhões de parâmetros. Em português.
Reza a lenda que alguns modelos com 34 bilhões de parâmetros alcançam o mesmo nível de Inteligência Artificial que o ChatGPT 3.5, mas aí é pra gente com pelo menos uma RTX 4090.
4 – A Era dos Modelos Multimodais
A maioria dos Large Language Models (LLMs) só aceita texto, mas alguns pesquisadores ampliaram isso. Surgiram vários modelos capazes de entender não só texto digitado, como áudio e até imagens. O LLaVA (Large Language and Vision Assistant) é o mais popular.
A configuração é surpreendentemente simples pra quem é confortável fuçando com python. O framework usado é o Llama.cpp, e os modelos estão disponíveis no repositório oficial do LlaVA.
O que dá para fazer com ele? Bem, é possível conversas como esta. Note que ele identificou uma capa de revista, acertou o nome e quando eu pedi a modelo da capa (imagem escolhida aleatoriamente, claro) a Inteligência Artificial deduziu que o nome em destaque deveria ser o nome da tal moça.
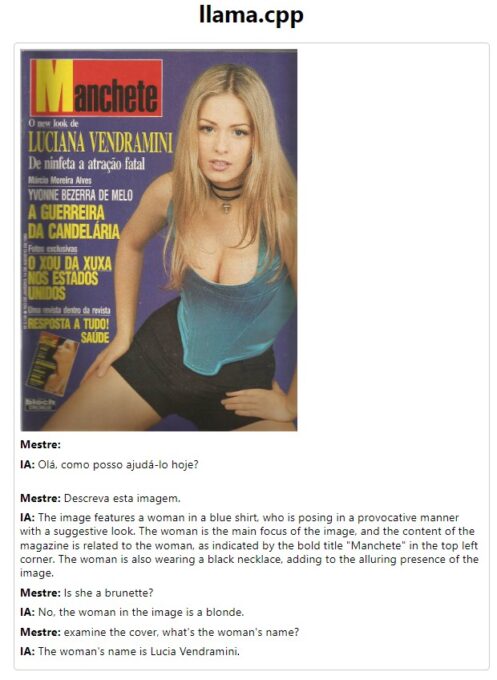
As possibilidades dessa tecnologia são quase infinitas.
Lembre-se, esse é um modelo simples, de 7 bilhões de parâmetros, rodando localmente numa GPU media (RTX 3060). Já é o suficiente para legendar de forma extensiva todas as minhas fotos, incluindo tags. Posso escrever um sistema de monitoramento que toque um alarme cada vez que alguém com camisa <daquele time> pare no meu portão.
5 – Stable Diffusion XL
O Stable Diffusion original foi lançado em agosto de 2022, e já foi um furor, até então o máximo da geração de imagens via IA era o DALL-E Mini, que era promissor, mas muito, muito incipiente ainda. O Stable Diffusion trouxe uma flexibilidade nunca vista.
Quase um ano depois, no final de julho de 2023, saiu o Stable Diffusion XL, com capacidades muito maiores, modelo treinado em 1024x1024, ao invés do 512x512 do Stable Diffusion comum, e uma qualidade final impressionante, veja a comparação:

Esquerda SD 1.5, direita, SD XL (Crédito: Stable Diffusion)
A forma mais simples de rodar o Stable Diffusion XL é com o Fooocus, que vem com um instalador stand alone.
6 – GUIs GUIs e mais GUIs
Originalmente o Stable Diffusion era um script em python, você preenchia alguns dados num arquivo JSON, rodava a inferência e catava o resultado em uma pasta. Surgiram rapidamente interfaces para facilitar o uso. As mais famosas são:
- AUTOMATIC1111 – Criada por um sujeito meio controverso, é uma interface excelente, mas demora muito para ser atualizada, às vezes até um mês. Muita gente a mantém instalada por ter uma base enorme de extensões.
- SD.NEXT – Criada como um fork da Automatic, a SD.NEXT é muito mais atualizada, trazendo novidades primeiro.
- INVOKE.AI – É a melhor interface para inpainting e outpainting, mas não tem tantas extensões quanto a AUTO.
- STABLESWARMUI – Em teoria é a interface oficial.
- EASYDIFFUSION – É uma interface mais simples, boa para quem não tem muitos recursos computacionais e não que se assustar com algo mais complexo.
- FOOOCUS – É uma interface bem simples, com muitos recursos escondidos nas opções avançadas. É focada (dsclp) no Stable Diffusion XL, e otimizada para GPUs fraquinhas, ele rodava mesmo na minha GeForce 1050ti com 4GB de VRAM. É a instalação mais fácil de todas.
- COMFYUI – É a interface mais poderosa, e você desenvolverá uma relação de amor e ódio. Comfy é baseada em nós, uma estrutura familiar pro povo do Blender e do After Effects, mas completamente alienígena para pessoas normais.
Por outro lado, Comfy é extremamente rápido e tem o menor consumo de memória entre as GUIs para Stable Diffusion.
7 – LCM
O Latent consistency model (LCM) foi uma inovação no Stable Diffusion. Com ele é possível gerar imagens muito rapidamente. Uma imagem comum precisa de uns 20 passos iterativos até se tornar coerente. Com LCM conseguimos isso em 4 ou 5.
Surgiram demos onde uma tela de desenho era acoplada ao Stable Diffusion, você rascunhava e ele criava a imagem com base no que você desenhou. Em tempo real.
Em dois dias apareceu uma integração: Um plugin incorporou o Stable Diffusion ao Krita, um excelente programa de ilustração Open Source. Veja o bicho em ação:
8 – LCM é tão semana passada... SDXL Turbo
Anunciado literalmente ontem, o SDXL Turbo é uma mega-otimização do Stable Diffusion XL, ele consegue gerar imagens coerentes com uma única iteração. Em frações de segundo você tem uma imagem.
Em tempo recorde, o povo do ComfyUI criou uma implementação, que funciona maravilhosamente bem, mesmo em GPUs com 6GB de VRAM. Instalei, e aqui um exemplo em tempo real do SDXL Turbo:
Óbvio que a qualidade final não é a mesma do Stabel Diffusion rodando repleto de LORAs, Control Nets e outras firulas, mas não é essa a proposta. O que temos aqui é um bloco de rascunho, onde podemos testar idéias, composições, formatos, e depois que estivermos satisfeitos com o prompt, aí sim rodar no workflow mais pesado
9 – Stable Diffusion Video
Uma semana antes do SDXL, a Stability AI anunciou o Stable Diffusion Video, uma versão do modelo de Inteligência Artificial capaz de gerar vídeos coerentes, com 14 ou 25 frames de duração.
Extensões como a AnimateDiff permitem gerar animações até razoáveis, mas o Stable Diffusion Video vai além. Ele recebe uma imagem estática como base, e através de uma tecnologia indistinguível de magia (meus antepassados fugiram do Monolito) deduz a movimentação dos objetos em cena.
De todas essas tecnologias o Stable Diffusion Video é a mais iniciante, mas seu potencial é quase infinito. Daqui a 5 anos (que em anos de IA equivale a seis meses) vamos ter capacidade de gerar vídeos coerentes sem limite de tempo.
Conclusão
Muito mais aconteceu em 2023 no mundo da Inteligência Artificial, deixei de lado todo o drama da OpenAI e a saída momentânea de Sam Altman, DALL-E 3, o fiasco do Microsoft CoPilot (pronto, falei) , as brigas exigindo regulamentação, e toda a questão sobre uso indevido (sobre isso escreverei no Contraditorium).
Este artigo é mais uma desculpa pra dar uma lista de links e caminho das pedras pra quem quiser aprender a brincar com IA, e acho que consegui. De qualquer jeito, fiquem com esta paisagem de Angra, que nunca pensei ver de novo em movimento, mas graças à Inteligência Artificial, aqui estamos!


