StableDiffusionXL e Fooocus - Tutorial Completo
StableDiffusionXL é a mais nova versão da tecnologia de geração de imagens via IA, agora bem mais simples de instalar e configurar
![]() Carlos Cardoso 3 anos atrás
Carlos Cardoso 3 anos atrás
StableDiffusionXL é uma nova e mais poderosa versão do StableDiffusion, um modelo de geração de imagens via Inteligência artificial lançado originalmente em agosto de 2022.
- Imagens via Redes Neurais e o assustador futuro da IA
- Aprenda a gerar imagens incríveis com o Stable Diffusion

Imagem gerada pelo StableDiffusionXL, sem retoques (Crédito: Stable Diffusion)
Nós* descrevemos em detalhe como funciona o modelo de geração de imagens do StableDiffusion neste artigo aqui, mas vamos a um rápido resumo:
NOTA: Eu concordo com a frase erroneamente atribuída a Mark Twain, “Somente monarcas, editores e pessoas com tênias têm o direito de usar o ‘nós’ editorial”, mas é um (mau) hábito que ainda tem o benefício de diluir a culpa quando eu, digo, nós escrevemos alguma besteira.
Voltando: Nosso cérebro é excelente em reconhecer e inferir padrões. Nós olhamos para as estrelas, e vemos batalhas épicas, deuses e heróis, usando apenas algumas linhas imaginárias entre pontos brilhantes no céu.
Nuvens viram dragões, pessoas, personagens de nossa cultura. Um anúncio clássico demonstra como toda uma cachoeira de emoções pode ser desencadeada com traços simples:

Um mínimo de traços despertam montes de emoções (Crédito: Reprodução Internet)
Em todo curso de desenho ensinam aquelas ilusões básicas que dão nó no cérebro: É um vaso ou uma pessoa em silhueta? Onde é o espaço negativo dessa imagem?
Toquinho dizia que com 5 ou 6 retas é fácil fazer um castelo. Alguns diriam que nem precisa disso tudo.
A habilidade de reconhecer um padrão, um objeto determinado em meio a ruído é algo presente em nossos cérebros, mas também dá para ser ensinado a uma Inteligência Artificial.
Um dos métodos, usado nesse caso pelo Stable Diffusion, é ensinar a Inteligência Artificial a encontrar padrões em meio a ruído aleatório. Isso é feito treinando a IA de trás pra frente.

Encontrando padrões no ruído. (Crédito: MeioBit)
A IA é apresentada, por exemplo, com a foto de um cachorro, e ensinada que aquilo é um cachorro. A mesma foto é salpicada com ruído aleatório, apresentada de novo. Isso se repete até a imagem ser 100% ruído.
Isso é feito repetidas vezes, com milhões de imagens, até a IA ter aprendido a olhar uma imagem composta apenas de ruído aleatório, e identificar padrões. Ela então vai removendo ruído, até chegar a uma imagem nítida do que acha ter visto em meio ao ruído.
A beleza da coisa é que não é nenhuma das imagens originais, o StableDiffusion guarda apenas os conceitos, uma representação matemática da imagem, e como é tudo basicamente matemática, combinar imagens e conceitos é apenas álgebra linear e matemática matricial.
O Stable Diffusion original, lançado em agosto de 2022 é uma rede neural com 859.52 milhões de parâmetros, treinado em imagens com resolução de 512x512. Ele tem várias deficiências, como não saber contar e se enrolar bastante desenhando mãos. Expliquei em detalhes o motivo disso aqui neste artigo.
A versão Stable DiffusionXL, lançada em julho de 2023 tem 3.5 bilhões de parâmetros, foi treinada com imagens de 1024x1024 (4 vezes a resolução do Stable Diffusion original) e foi refinada para lidar bem melhor com mãos, texto e luz.

Imagem gerada pelo StableDiffusionXL, sem retoques (Crédito: Stable Diffusion)
A qualidade geral do Stable DiffusionXL é impressionante. Iguala ou supera o Midjourney, em algumas situações, mas isso tem um preço. A performance leva uma paulada. Para piorar, inicialmente nenhuma das implementações Open Source do Stable Diffusion funcionavam com a versão XL. Quando começaram a funcionar, as demandas de VRAM eram irreais. Automatic1111, a versão mais popular, não rodava com menos de 16GB de VRAM. Por sorte a comunidade correu atrás, e otimizações foram alcançadas.
A primeira versão a rodar com qualidade o Stable DiffusionXL foi a ComfyUI, mas para quem está acostumado com simples menus e controles, Comfy é um pesadelo. Ela é toda baseada em nós, e para gerar uma imagem você precisa fazer algo assim:
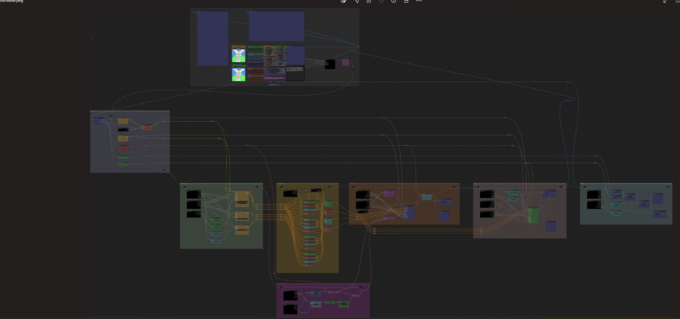
Interface do ComfyUI. (Crédito: MeioBit)
E pode piorar, MUITO. Acredite.
Seguindo o caminho oposto, foi criada a Fooocus, com a proposta de ser uma interface Open Source, extremamente simples, otimizada até o osso, dedicada ao Stable DiffusionXL. Os maníacos conseguiram fazer a danada funcionar até na minha arcaica GeForce 1050ti com míseros 4GB de VRAM.
Eu tive zero erros de memória com o Fooocus, zero. Não perdi nenhuma geração por erros OOM, nenhuma. E a instalação é uma brisa.
Pré-Requisitos para rodar Fooocus e Stable DiffusionXL
Dizem que o Stable DiffusionXL é bem exigente em termos de hardware, mas não é bem assim. Para treinar checkpoints e LoRAs, sim, ele demanda muito hardware, mas para gerar imagens, é possível usar máquinas bem básicas.
Como requisitos mínimos temos:
1 – CPU – Qualquer uma minimamente decente, um Ryzen 5 já atende.
2 – GPU – Eu rodo com uma GeForce 1050ti com 4GB de VRAM, é uma GPU de 2016, 7 anos de idade em termos de informática é MUITO tempo. Considere a 1050ti como requisito mínimo, mas atenção: O Fooocus é feito para rodar com GPUs nVidia, ele não funciona com AMDs.
3 – HD – Na verdade, SSD. O Stable DiffusionXL movimenta quantidades imensas de dados entre CPU, GPU e disco. Tenha pelo menos 40GB livres em um SSD, de preferência NVME. Óbvio que você pode usar até um HD mecânico, mas não me responsabilizo pela frustração de ficar esperando.

Imagem gerada pelo StableDiffusionXL, sem retoques (Crédito: Stable Diffusion)
Instalando o Fooocus e o Stable DiffusionXL
Primeiro passo, você vai criar um diretório de nome Fooocus, na raiz do seu disco C:. Ou em outro disco, tanto faz, o importante é que seja um SSD, ou tudo será muuuuito lento.
Segundo passo: Visite o repositório oficial, em https://github.com/lllyasviel/Fooocus e na lateral direita, clique em Releases, procure a versão mais atual. Neste momento é a 1.0.35.
Terceiro passo: Clique no arquivo Fooocus_win64_<versão>.7z, ele começará a ser baixado. A versão atual tem 1.56GB, então dependendo da sua Internet, vai demorar um tiquinho.
Quarto passo: Copie o arquivo baixado para o diretório Fooocus que você criou.
Quinto passo: Clique no arquivo com o botão direito e selecione a opção “Extrair Aqui/Extract Here”, conforme o idioma do seu Windows. Caso ele não reconheça a extensão .7z, instale o WinRAR, e repita.
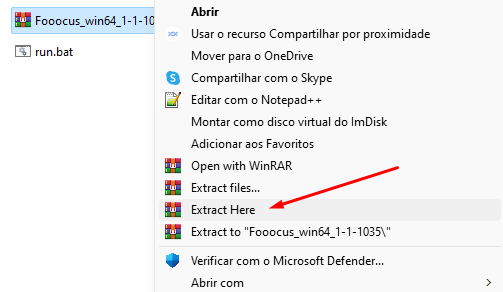
O Winrar tem trial. (Crédito: MeioBit)
Depois de uma considerável quantidade de tempo, você terminará com dois diretórios e um arquivo run.bat, além do arquivo original .7z, que você pode apagar para liberar espaço.
Sexto passo: duplo-clique no run.bat, isso abrirá uma janela do DOS (eu sei!) que fará a instalação inicial, baixando automaticamente o chekpoint (modelo) do Stable DiffusionXL e o refiner, um modelo auxiliar que deixa as imagens ainda melhores.
Um tem 6.7GB, o outro 5.9GB, então pode demorar um certo tempo.
Você não precisa fazer mais nada. Se tudo der certo ele irá carregar o Stable DiffusionXL e abrir uma janela em seu browser para o endereço http://127.0.0.1:7860/, exatamente como esta:
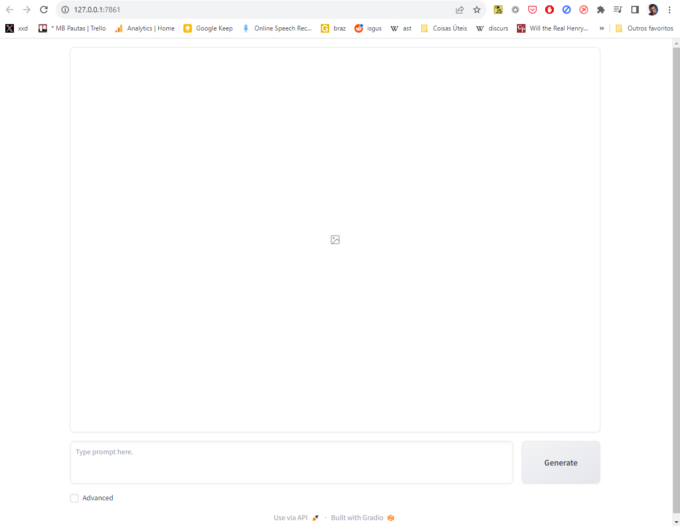
Minimalista, diria eu (Crédito: MeioBit)
E é isto. Tudo pronto. Tudo que você precisa fazer agora é escrever seu prompt, descrevendo (em inglês) que quer que o Stable DiffusionXL crie. No exemplo abaixo, pedi a Princesa Peach como Princesa Leia.
Depois de clicar em GENERATE e esperar um tempo razoável, você é agraciado com duas imagens. Elas ficam armazenadas na pasta C:\Fooocus\Fooocus\outputs, se você copiou as instruções de instalação sem alterar nada.
Fooocus – Modo Avançado
O Fooocus tem como principal ponto de venda a facilidade de uso, é literalmente uma interface com um único botão, mas ele tem recursos mais avançados, basta selecionar a caixa “Advanced”, no canto inferior esquerdo.
Isso abrirá uma área no lado direito da janela, com diversos recursos. Vamos estudar um a um.
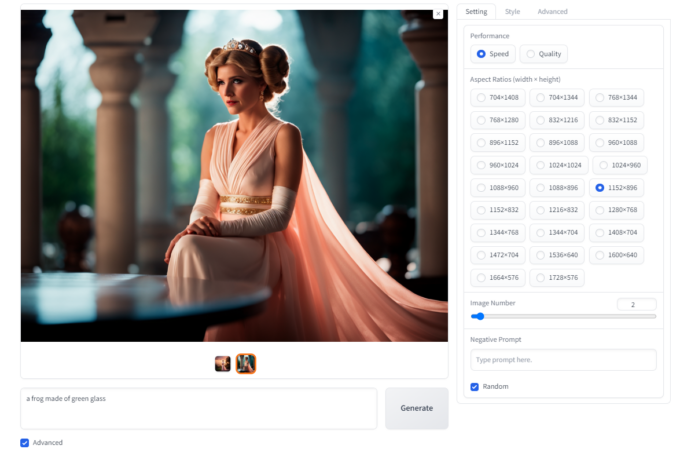
Fooocus em modo avançado. (Crédito: MeioBit)
Settings
É a primeira aba. Descendo, o primeiro campo é:
Performance – Essa é auto-explicativa. Deixando em Speed, o processo de geração da imagem leva 30 passos. Colocando em Quality, esse valor aumenta para 60, dobrando o tempo mas produzindo um resultado às vezes bem melhor.
Aspect Ratios – O Stable DiffusionXL é treinado com imagens em formato 1024x1024, mas seu mecanismo de geração foi otimizado para outras resoluções além dessa, evitando muitos dos erros e aberrações da versão anterior. Nesta área você seleciona as dimensões da imagem que quer gerar.
Image Number – Quantas imagens o Stable Diffusion irá gerar quando você clicar em Generate. O padrão são duas, eu recomendo que baixe para uma, até ter refinado seu prompt.
Negative Prompt – É um recurso onde você descreve tudo que não quer na sua imagem. Você pode pedir uma cesta de frutas no seu prompt, e colocar “banana” no negative prompt, para gerar uma cesta banana-free.
Random – este campo define a semente da imagem, um valor numérico usado para gerar o ruído aleatório do qual o Stable Diffusion extrairá a imagem. Usando os exatos mesmos parâmetros, incluindo a semente, você consegue reproduzir a mesma imagem várias vezes. Isso é bem útil quando queremos manter a imagem mas mudar o estilo.
E por falar em estilo, temos a aba Style.
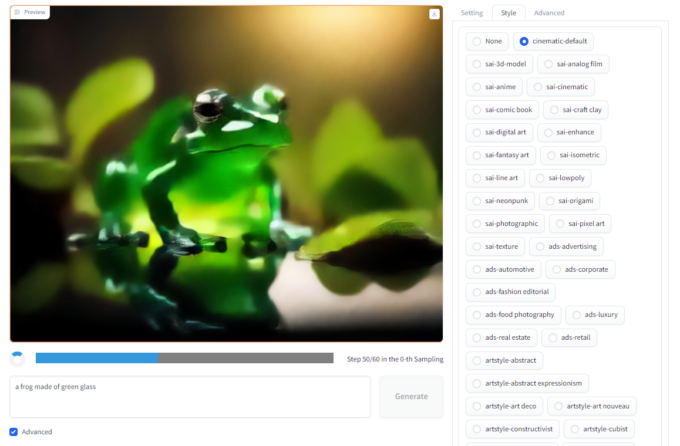
Aba de estilos (Crédito: MeioBit)
Style – Essa aba é na verdade um atalho, você pode definir o estilo da imagem descrevendo-o no prompt, mas aqui o foco é facilidade, então você pode selecionar um estilo específico, e todos os prompts seguirão aquele estilo. São 143 estilos diferentes pré-programados.
Neste link aqui há exemplos de todos eles.
Advanced
Esta aba começa com os campos SDXL Base Model e SDXL Refiner. Se você quiser economizar tempo, pode selecionar o refiner como “none”. Muita gente fica satisfeita com os resultados do checkpoint puro.
Normalmente você não precisa mexer no Base Model, mas se usar modelos diferentes do padrão, é aqui que os seleciona. A instalação é bem simples, basta baixar o modelo novo para seu PC e colocá-lo na pasta C:\Fooocus\Fooocus\models\checkpoints.
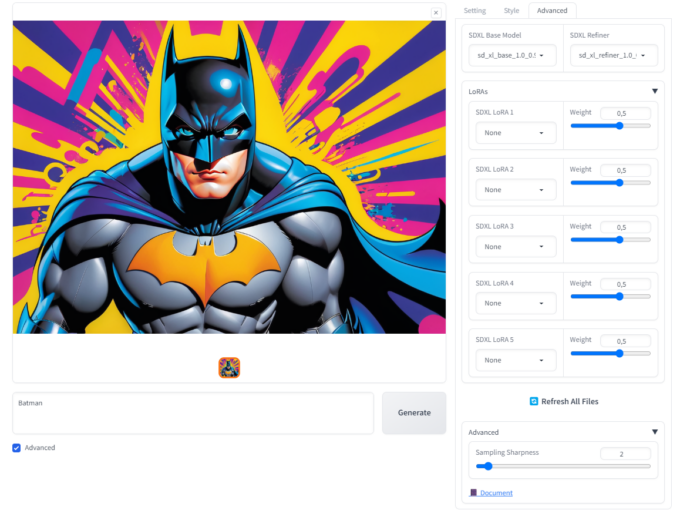
Aba Advanced. (Crédito: MeioBit)
Você encontra checkpoints treinados para o SDXL em sites como o https://civitai.com/, mas CUIDADO, o site tende a ser bem NSFW, não clique se o chefe estiver passando.
LoRAs – Uma LoRA, Low Rank Adaptation é um arquivo treinado com objetos ou conceitos, que é integrado a um checkpoint maior. Digamos que eu quero gerar imagens de uma pessoa específica, que não faz parte da base de treinamento do Stable Diffusion. Eu posso treinar um ckeckpoint inteiro adicionando a pessoa, o que leva bastante tempo, ou posso treinar uma LoRA, bem mais rápido e com menos recursos.
A beleza da LoRA é que quando treinada com um conceito, ele pode ser aplicado a qualquer coisa, como por exemplo a LoRA do uniforme da Starlight, de The Boys.
O Fooocus dá a opção de incluir 5 LoRAs no modelo, o controle deslizante “Weight” determina o peso que cada LoRA terá. Por default você só tem uma LoRA de demonstração instalada, mas basta baixar do Civit.ai e jogar no diretório C:\Fooocus\Fooocus\models\loras.
Advanced
Aqui temos a opção Sampling Sharpness, ela ajuda a remover o “excesso de perfeição” de algumas imagens, tornando-as mais realistas e com detalhes e imperfeições.

Imagem gerada pelo StableDiffusionXL, sem retoques (Crédito: Stable Diffusion)
Problemas com Lentidão
Usuários do Stable Diffusion descobriram que seus sistemas estavam dando menos erros de memória, mas a velocidade de geração caiu em 10x. Imagens que levavam um minuto passaram a demorar mais de 10 minutos.
A culpa disso foi da Nvidia, que implementou um swap de memória em seu driver. Ao invés de abortar a operação por falta de VRAM, o driver usa RAM via CPU como memória auxiliar, mas a degradação de performance é imensa.
A solução é cancelar as atualizações automáticas e instalar no máximo a versão 531.79 dos drivers da Nvídia.
Dicas de Prompts
O método mais fácil de aprender como escrever prompts é estudando o trabalho dos outros. Na galeria do Civit.ai temos milhares de imagens de alta qualidade. Clicando no ícone com um “i” no canto inferior direito das imagens, temos acesso ao prompt, prompt negativo e outros parâmetros de geração. Como no Fooocus vários desses parâmetros não estão acessíveis, você não conseguirá gerar uma imagem idêntica, mas o prompt já é meio-caminho andado.
O log
Dentro do diretório com as imagens geradas salvas, você encontra um arquivo chamado log.html, clique duas vezes e ele abrirá no seu navegador, listando todas as imagens salvas naquela pasta, bem como seus parâmetros de geração.

Imagem gerada pelo StableDiffusionXL, sem retoques (Crédito: Stable Diffusion)
Performance
Na minha praquinha, uma imagem de 1152 x 832 leva cinco minutos para ser gerada. Com o Stable Diffusion 1.5 uma imagem de 512x512 leva pouco mais de um minuto. Não que eu seja parâmetro, estou no low end do low end, mas a verdade é que eu levaria meses estudando Blender para fazer uma imagem dessas, e no final desistiria pois simplesmente não sei desenhar.
Conclusão
Fooocus é a instalação mais simples e amigável do StableDiffusionXL. Obviamente um monte de recursos não estão disponíveis, como extensões, parâmetros extras, etc, mas não é essa a proposta.
Ele é uma porta de entrada para o mundo das imagens geradas por IA, sem burocracia, complicação ou exigência de conhecimentos arcanas de computação. É uma forma de você molhar os pés antes de se aventurar a mergulhar.
Então, divirta-se, mas lembre-se: Grandes poderes trazem grandes responsabilidades


