Aprenda a gerar imagens incríveis com o Stable Diffusion
Stable Diffusion é um software para geração de imagens via IA. É Livre, Open Source e aqui você aprenderá a instalar e usar
![]() Carlos Cardoso 4 anos atrás
Carlos Cardoso 4 anos atrás
Stable Diffusion é uma aplicação de IA e Redes Neurais, capaz de criar imagens à partir do “nada”. Neste artigo aqui detalhamos o seu funcionamento. Agora vamos aprender como instalar e configurar o software, e usá-lo em casa, com toda a liberdade que isso traz.
- Imagens via Redes Neurais e o assustador futuro da IA
- Parece Harry Potter, mas é ciência: imagens animadas por IA

Levei menos de 2 minutos pra criar essa imagem (Crédito: Carlos Cardoso / Stable Diffusion)
A versão original do Stable Diffusion roda em Jupyter Notebook e Python, mas como o software foi disponibilizado em regime de Open Source, ele foi forkeado e adaptado para diversas plataformas. Outro dia um maluco do Reddit desenvolveu uma versão pra iPhone.
Essas versões locais usam a linguagem Python e módulos como PyTorch, um port do Torch, um framework para Machine Learning bem popular. Se você é programador, já pesquisou o caminho das pedras e achou esse meta-guia no Reddit. Do contrário, vem comigo!
Requisitos Mínimos
A versão do Stable Diffusion que vamos utilizar tem requisitos bem modestos. Normalmente o pessoal usa GeForces RTX 3090, placas com 12, 24GB de memória de vídeo, e os pesquisadores de IA/Machine Learning usam placas profissionais com dezenas e dezenas de gigabytes, e preços que fariam até o Linus Sebastian ficar sem-jeito.
Felizmente a comunidade conseguiu otimizar bastante os requisitos. Há quem diga que até placas com 2GB de VRAM funcionam, mas eu estou rodando em uma GeForce 1050ti com 4GB e é o mínimo aceitável, mas funciona perfeitamente. Importante é ser nVidia, as AMDs não possuem a tecnologia CUDA oferecia pelas geForces.

O prompt dessa é bem simples: "delicious rich breakfast, high details, HD, 8k" (Crédito: Carlos Cardoso / Stable Diffusion)
Em teoria, e até na prática é possível rodar Stable Diffusion apenas com sua CPU, mas o tempo de execução é intolerável.
Em termos de RAM, o consumo é pífio, com 8GB você estará bem-servido. Então, se sua placa de vídeo é minimamente decente, sigamos adiante.
Como Baixar
Existem dezenas de versões do Stable Diffusion, para iniciantes a mais amigável é esta, encontrada no GitHub, na URL:
https://github.com/cmdr2/stable-diffusion-ui
No momento eles estão na versão v2.16 mas isso muda todo dia. Você acha a versão mais atual neste link aqui:
https://github.com/cmdr2/stable-diffusion-ui/releases
Há dois arquivos principais, uma versão para Linux e o arquivo stable-diffusion-ui-win64.zip, que é o que você vai baixar. Copie o arquivo para a raiz do disco C:.
Feito isso, no Windows Explorer clique no arquivo com o botão direito, e selecione a opção “Extrair Tudo”. Ele vai sugerir a pasta C:\stable-diffusion-ui-win64. Troque por C:\
O diretório C:\ stable-diffusion-ui será criado. Agora vamos para a parte mais assustadora para usuários (e sejamos honestos, desenvolvedores) com menos de 30 anos: A Linha de Comando. Em tempos de IDEs, GUIs em Visual Basic para rastrear IPs e outras tecnologias visuais, o usuário médio nem chega perto da linha de comando, mesmo em Linux hoje em dia dá pra ser um usuário com sem abrir um bash da vida.

Pronto para abrir a Caixa de Pandora? - Prompt: photography, a woman in greek classic clothes, blonde, tiara, long braided hair, ((holding an decorated small wooden box with the lid open)), a green mountain field, ultra realistic, intricate details, highly detailed. 8 k, 8 5 mm, centered, wide angle
Negative prompt: distorted, warped, bad anatomy, twisted, cross eyed, closeup, smeared, cartoon (Crédito: Carlos Cardoso / Stable Diffusion)
Princípios Básicos
Nós vamos trabalhar inicialmente no prompt de comando, pessoal mais antigo simplesmente chamaria de DOS, é errado, mas você não vai mencionar isso.
Clique no menu iniciar do seu Windows, digite “Prompt de comando”, e execute a aplicação. Deverá abrir uma janela preta, com algo parecido com isto:
Microsoft Windows [versão 10.0.22000.1042] (c) Microsoft Corporation. Todos os direitos reservados. C:\Users\cardo>
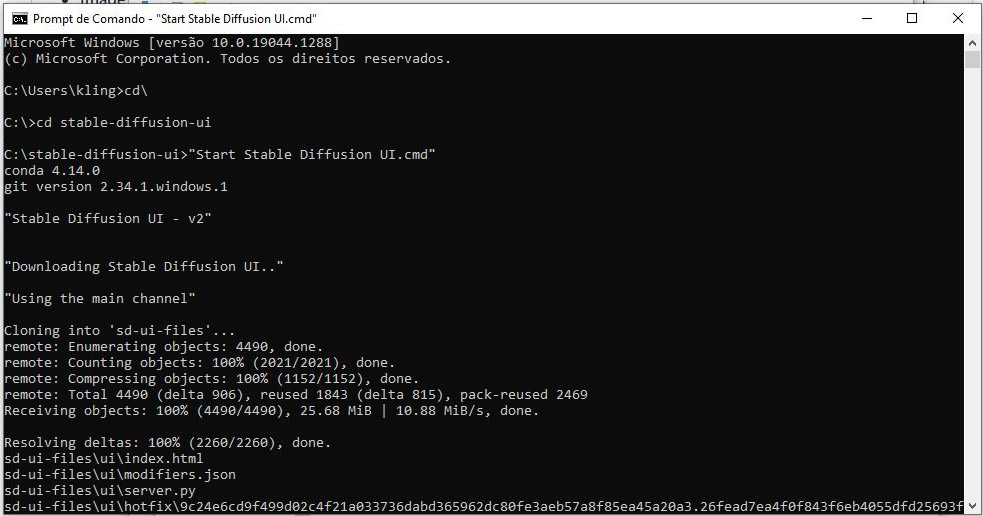
O prompt do DOS (Crédito: Carlos Cardoso)
Você está no seu diretório de usuário. Com um CD\ <enter> você vai pra raiz do disco. Calma, estamos quase lá. Agora vamos mudar para o diretório da aplicação. Digite:
CD stable-diffusion-ui <enter>
Digitou? Não precisava. Bastaria escrever stab, apertar TAB e o nome do diretório se autocompletaria.
Agora vamos iniciar a brincadeira: digite Start Stable Diffusion UI.cmd <enter>
OK, você já sabe que basta digitar start, apertar TAB e a linha se autocompletará. <ENTER>, sente e relaxe. O script vai instalar Python, Pythorch, Stable Diffusion, os modelos, scripts auxiliares, módulos, o minerador de Bitcoin que vai pagar meu clone da Luciana Vendramini, tudo.
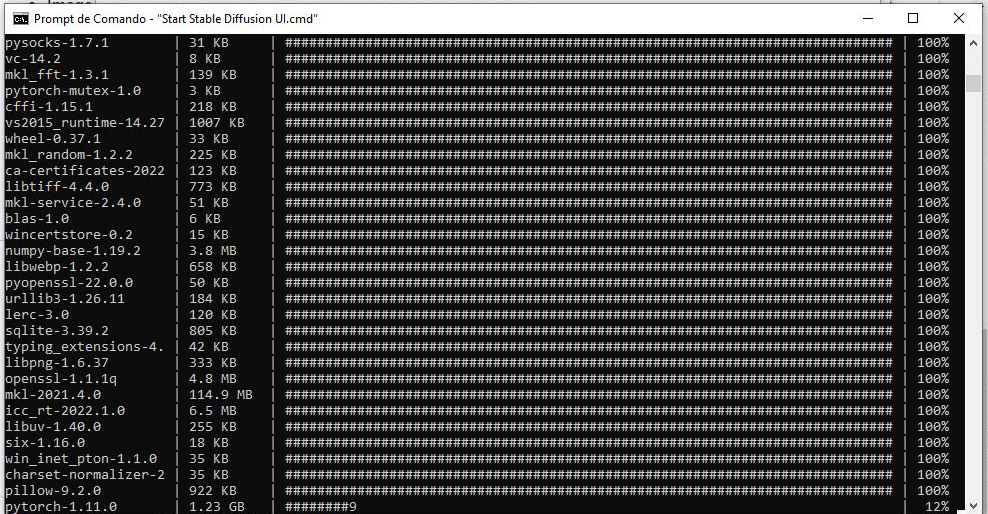
Você verá algo assim. (Crédito: Carlos Cardoso)
Depois que o Stable Diffusion terminar de instalar e iniciar o webserver, seu Windows provavelmente vai reclamar, abrindo uma tela do Firewall bloqueando o SD. Clique em permitir:
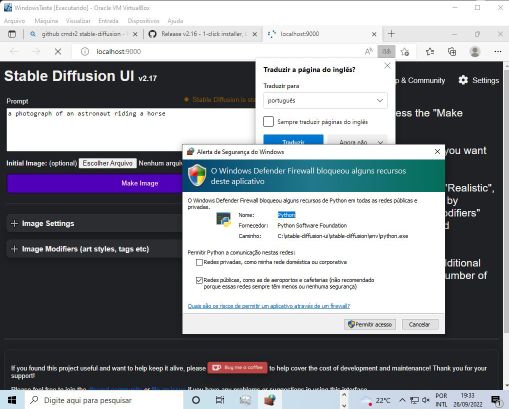
Firewall do Windows barrando o Stable Diffusion (Crédito: Carlos Cardoso)
Dependendo do seu link, vai demorar bastante, bastante mesmo, mas eventualmente o script vai instalar tudo, incluindo um webserver e comandará a abertura de seu navegador web, no endereço http://localhost:9000/
Você verá uma tela como esta:
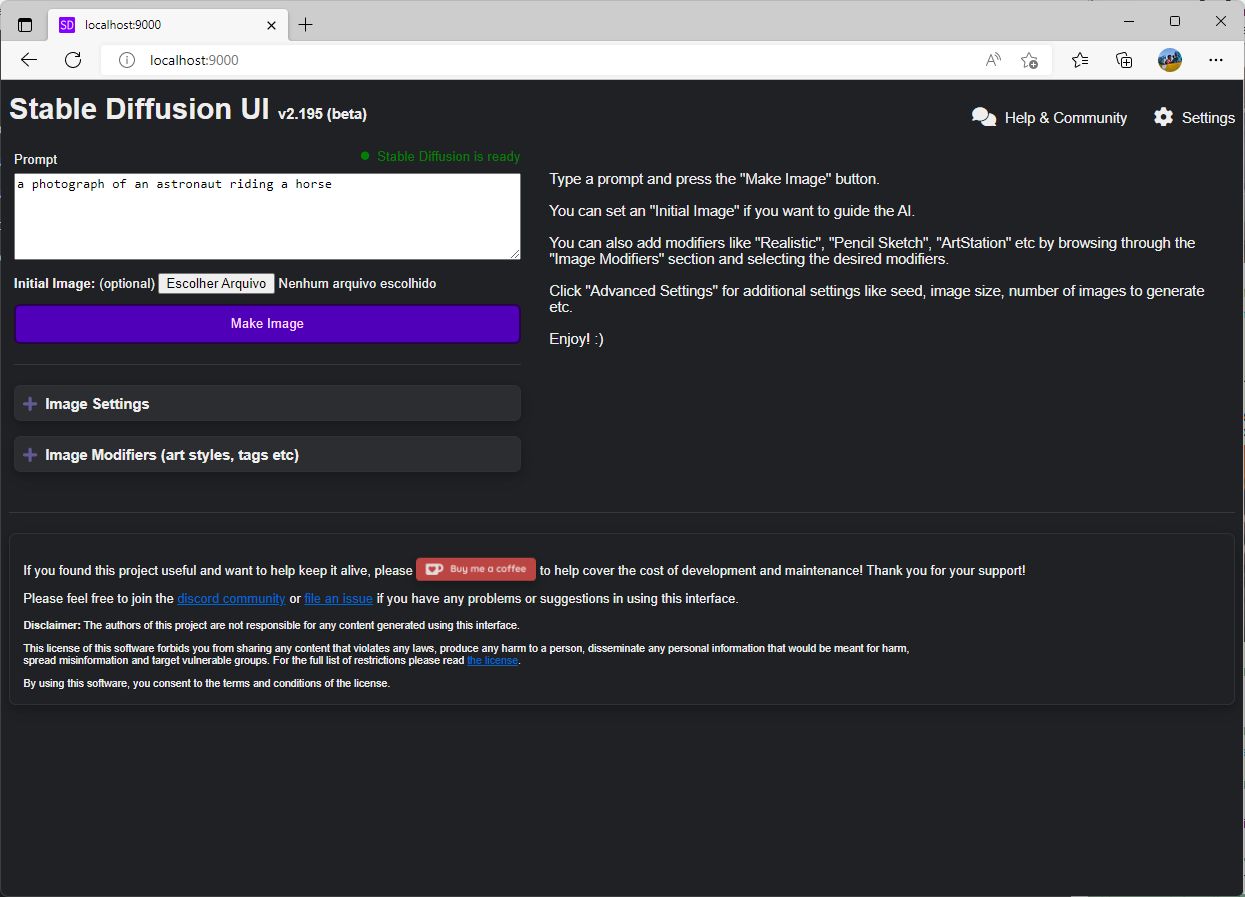
Tela inicial do Stable Diffusion
Seu primeiro passo é clicar em “Settings”, no canto superior direito. Ali temos várias opções.
A primeira, “Automatically save to”, sugiro que você crie uma pasta “imagens-ia” na raiz do seu disco c:, habilite a opção e coloque c:\imagens-ia como caminho, assim não perderá nenhuma imagem que criar.
A segunda opção, “Play sound on task completion” também é bom ativar, às vezes a gente esquece que está “rodando um job” e o “ping” avisa quando tudo terminou.
Turbo Mode, a 3ª opção, acelera o processamento, mas come 1GB de memória. Incrivelmente mesmo na minha 1050ti com 4GB, ele pode ser acionado e ainda funciona tudo, sem erros de memória.
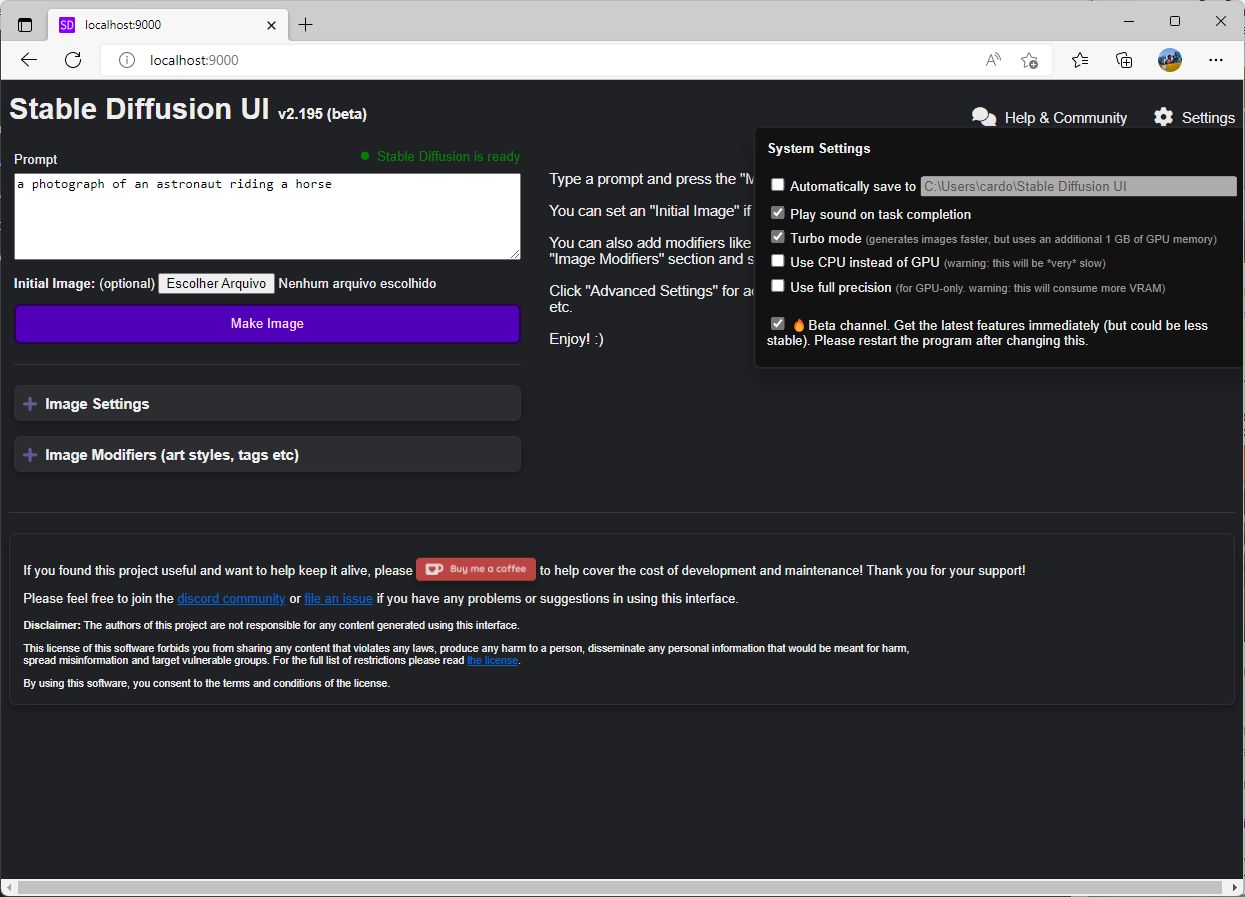
GUi do Stable Diffusion, com a opção de settings ativada.
Use CPU instead of GPU. Não habilite isso, eu consigo 2.5s/iteração na minha GPU. Passando pra CPU esse tempo sobe pra 28.44s/iteração.
Use Full Precision em teoria geraria uma imagem melhor, mas essa sim come memória de vídeo demais, então todas as imagens que você está vendo neste artigo foram feitas com precisão simples.
Beta Channel é o canal. Marque essa opção, ela libera todos os recursos experimentais na versão beta do Stable Diffusion UI.
Do Outro ladinho da Stable Diffusion
A primeira opção é o Prompt, que é a descrição textual da imagem que queremos gerar. Aqui, vale a sua imaginação. Quanto mais a descrição, melhor a imagem. Vejamos esta descrição de Julieta:
“Juliet is very young, about 14 years old. She has long, dark brown hair and dark brown eyes. She is very pale and wears a cross around her neck along with her red and yellow robes and dresses. She also wears a gold and red hairpiece.”
Traduzindo:
“Julieta é muito jovem, cerca de 14 anos. Ela tem longos cabelos castanhos escuros e olhos castanhos escuros. Ela é muito pálida e usa uma cruz no pescoço junto com suas vestes e vestidos vermelhos e amarelos. Ela também usa uma tiara dourada e vermelha.”
As descrições para o prompt precisam ser em inglês, então se você não domina o nobre idioma bretão, sempre pode usar o Tradutor do Google.
Cole a descrição no campo do Prompt, clique em Make Image e espere, em alguns segundos a imagem começará a ser gerada, e você verá feedback na lateral da tela.

Julietas. (Crédito: Carlos Cardoso / Stable Diffusion)
Se você comandar de novo a geração da imagem, ganhará outra Julieta, que corresponderá à descrição, mas será... diferente. Internamente o modelo do Stable Diffusion tem 890 milhões de parâmetros, então a variedade é garantida.
Note que como não informamos nada sobre o estilo da imagem, o SD pode escolher uma foto realista, anime, ilustrações, Lego, a lista é imensa.
Mais Parâmetros
Até agora só geramos imagens com os parâmetros default, mas o Stable Diffusion é capaz de muito mais. Clique no lado direito da janela, em Image Settings, opções se abrirão. Vamos por partes:
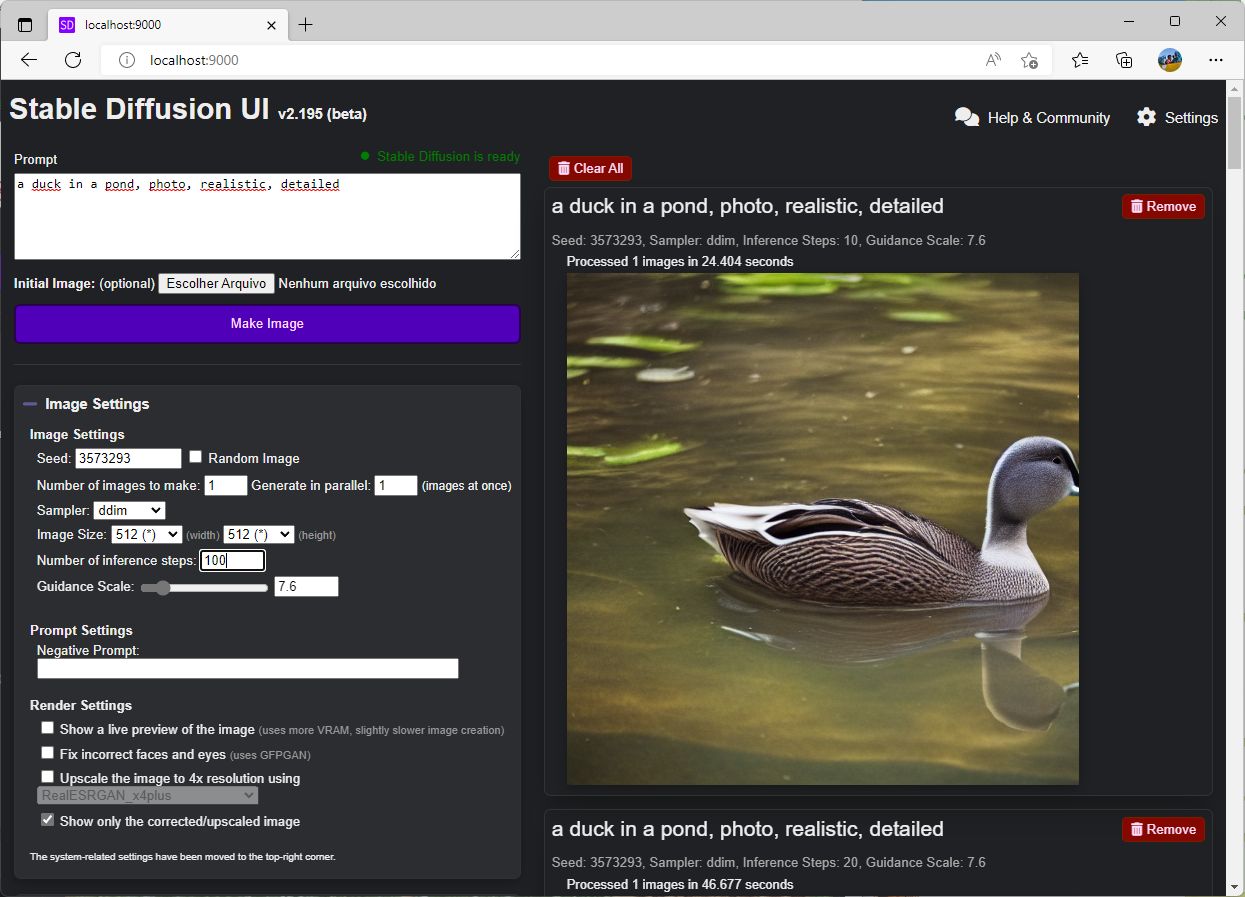
Parâmetros de imagem. (Crédito: Carlos Cardoso / Stable Diffusion)
Seed – É a semente, o número aleatório usado para gerar a imagem composta de puro ruído gaussiano, usada como base para o Stable Diffusion inferir a imagem que você mandou ele criar. A beleza aqui é que embora o ruído seja aleatório, se usarmos a mesma semente, ele gerará sempre o MESMO ruído aleatório. (na prática há variações, mas ficam bem mais contidas).
Você pode deixar a opção Random Image marcada, parar gerar imagens bem diferentes a cada execução, os especificar uma semente, se quiser produzir variações em cima de uma base.
Number of Images to Make e Generate in parallel – Aqui você escolhe quantas imagens quer fazer. Dependendo da sua GPU, pode escolher 10, 20, 60. Eu raramente passo de 5, em geral vou uma de cada vez, ajustando os parâmetros. A segunda opção permite que ele gere mais de uma imagem ao mesmo tempo, o que funciona para placas com recursos sobrando.
Sampler: Como já explicado neste calhamaço aqui, o Stable Diffusion cria imagens partindo de uma figura original de puro ruído. Há vários métodos para fazer a amostragem do ruído atrás de padrões. Esses métodos, Samplers, podem ser selecionados nesta opção. Alguns são mais rápidos do que outros, alguns produzem resultados melhores com menos iterações, mas são mais lentos. Recomendo que você experimente até achar a melhor combinação. Eu ainda não achei.
Image Size – Aqui obviamente é o tamanho da imagem, e isso influencia no resultado. Imagens verticais tendem a render imagens de corpo inteiro, se você não especificar. Imagens mais horizontais funcionam melhor para paisagens. O melhor formato, entretanto, é o quadrado.
O modelo do Stable Diffusion foi criado estudando milhões de imagens em formato 512x512, então esse é o formato com o qual ele se sente mais à vontade. Mesmo assim, nada impede que você brinque com as opções, mais cuidado. Imagens muito grandes provocarão erro de memória. No meu setup o limite é 768x512. Mas não se preocupe, há como gerar imagens bem maiores.
Number of inference steps – Aqui as coisas ficam interessantes. A IA foi treinada para tentar inferir uma imagem latente, com base no ruído aleatório, mas a primeira imagem inferida é pouco mais que um borrão. Essa imagem inferida é retroalimentada no sistema, que a usa como nova base, e tenta inferir uma nova imagem.

Mesmo prompt, variando o número de passos. (Crédito: Carlos Cardoso / Stable Diffusion)
A magia começa a acontecer -e rápido- e logo as imagens se tornam mais e mais complexas e detalhadas. Às vezes com 4 ou 5 iterações, já temos uma imagem decente. Fazendo com que o Stable Diffusion realize mais iterações em cima da mesma imagem, ela tende a melhorar bastante. A progressão, entretanto, não é linear. 20 iterações são suficientes para achar uma imagem preliminar, daí você pode subir para 30 ou 35. 50 gera uma imagem excelente, 60 fica um pouco melhor, mas daí em diante os ganhos são muito pequenos.
Guidance Scale – Essa configuração indica ao Stable Diffusion o quão restrito ele tem que ser na interpretação do prompt. Com valores por volta do 7, ele age com razoável precisão, mas bastante liberdade para variar. Aqui 6 imagens com o mesmo prompt, “a teenage anime girl with green hair and a yellow hair bow, sailor uniform, in a school yard, holding a white fluffy cat”, mesma semente – 320576 – Inference steps 6 e Guidance Scale 7.1

Japinha com guidance baixo. (Crédito: Carlos Cardoso / Stable Diffusion)
Vamos subir a Guidance Scale para 18.4, sem alterar nenhum dos outros parâmetros:

mais guidance, menos liberdade (Crédito: Carlos Cardoso / Stable Diffusion)
Negative Prompt – esse é um recurso experimental, usado para induzir o Stable Diffusion a não seguir certas tendências. O povo usa para corrigir alguns erros comuns, incluindo no negative prompt termos como “bad anatomy”, “extra limbs”, “plastic skin”.
No exemplo abaixo, seis japinhas renderizadas com o prompt “illustration of schoolgirls playing volleyball,sailor uniforms, long hair, at a beach, Anime”, Inference steps 25 e Guidance Scale 7.6.

Japinhas com meia (Crédito: Carlos Cardoso / Stable Diffusion)
Agora imagine que eu seja um daqueles otakus pervertidos, perdoe o pleonasmo, e goste de minhas japinhas como vieram ao mundo: Sem meias. Eu coloco “socks” no Negative Prompt, e eis o resultado:

Japinhas sem meias (Crédito: Carlos Cardoso / Stable Diffusion)
Show a live preview of the image – essa opção é mais por curiosidade, ele vai exibindo as imagens intermediárias de cada iteração, é bom para demonstrar, mas recomendo deixar desativado.
Fix incorrect faces and eyes – O Stable Diffusion está longe de ser perfeito, e ele não tem conceito de anatomia, muitas vezes se confunde e coloca membros onde eles normalmente não existem, não que haja nada de errado nisso.
O problema acontece bastante nos rostos, que às vezes saem distorcidos. Essa opção irá usar o GFPGAN, um algoritmo via IA, Deep Learning, etc para “consertar” rostos em fotos antigas, danificadas ou em baixa resolução.
Aqui um exemplo de restauração de rostos, usando imagens aleatórias de baixa resolução escolhidas randomicamente na Internet.
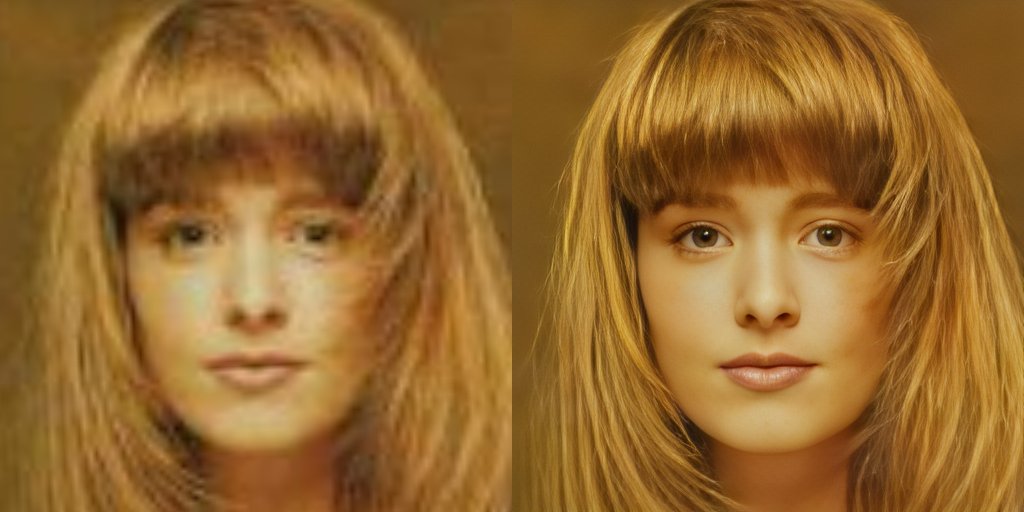
Restauração e ampliação de imagem via FGPGAN (crédito: Carlos Cardoso)
Se você quiser usar o Stable Diffusion para gerar rostos, essa opção é fundamental.
Upscale the image to 4x resolution – essa opção usa solução de IA tipo o ESRGAN para ampliar a imagem gerada. Isso é especialmente útil se você só consegue trabalhar em 512x512 e quer algo bem maior. Ela torna o tempo de geração da imagem um pouco maior, mas nada intolerável.
A opção final faz com que a interface só mostre a imagem final corrigida e ampliada, do contrário ele exibirá o antes e o depois.
Stable Diffusion – opções de imagem
Nas opções “Image Modifiers” você tem tags pré-programadas onde pode escolher o estilo do do traço – rascunhos, pontilhismo, etc e o estilo visual – cartoon, cubismo, Art Nouveau, CGI, litografia, etc.
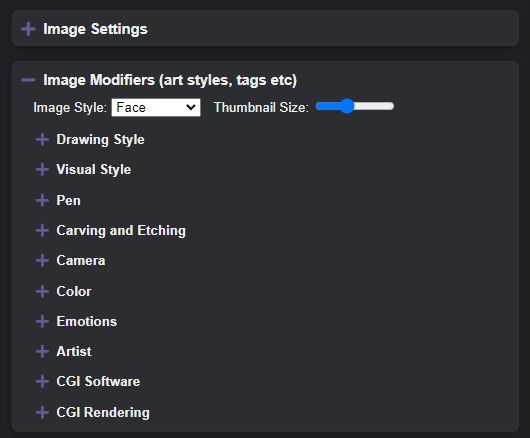
Opções de modificação da imagem. (Crédito: Carlos Cardoso / Stable Diffusion)
Selecionando essas opções e mantendo a semente, você consegue versões bem semelhantes da imagem, com estilos diferentes:

Mesmo prompt, mudando o estilo de imagem. (Crédito: Carlos Cardoso / Stable Diffusion)
Também é possível modificar a iluminação da cena, o tipo de câmera usada, lentes, hora do dia, escolher um estilo de um artista específico ou até mesmo o tipo de imagem, se é computação gráfica, qual engine de renderização... as opções são imensas, basta clicar no thumbnail e a opção será selecionada, adicionada lá em cima perto do prompt.

Emma Watson, por vários pintores famosos. (Crédito: Carlos Cardoso / Stable Diffusion)
Ah sim, você pode combinar mais de um termo, nesta imagem aqui eu combinei anime E cgi:
Agora o mais importante, pequeno gafanhoto: Essas opções nem sequer ARRANHAM as possibilidades. Imagine que o Stable Diffusion é seu artista particular. Quanto melhor você descrever o que quer que ele pinte, mais próximo será o resultado.
Esta imagem aqui por exemplo que eu roubei (o prompt) do Reddit:

Impressionante, eu sei. (Crédito: Carlos Cardoso / Stable Diffusion)
O prompt usado foi:
sexy cute woman, beautiful eyes, photorealistic face, photorealistic eyes, choker, portrait, intricate detailing, fantasy, d & d, by greg rutkowski and raymond swanland, boobs, sharp focus, trending on artstation, 8 k realistic digital art, cryengine, symmetric, league of legends splash art, concept art, frostbite 3 engine
com prompt negativo:
((poorly_drawn_face)), ((poorly drawn hands)), ((poorly drawn feet)), fat, (disfigured), ((out of frame)), (((long neck))), (big ears), (((poo art))), ((((tiling)))), ((bad hands)), (bad art), (((penis))), (((mutation))), (((deformed))), ((ugly)), cloned face, (missing lips), ((ugly face)), blurry, undefined, rough
Quanto mais descritivos, melhor.
Eu sugiro que você frequente a subreditoria do Stable Diffusion, procure por imagens que ache interessante, e estude os prompts usados, a maioria dos usuários compartilha os que usou.
O Stable Diffusion é um brinquedo maravilhoso, estamos tendo a rara oportunidade de experimentar uma tecnologia revolucionária, ainda em sua infância. Há toda uma comunidade de entusiastas que assim como eu e você, não são cientistas de dados, mas estão dispostos a fuçar, experimentar e descobrir os limites dessa tecnologia tão avançada que é indistinguível de magia.



