CUDA: A aposta da Nvidia que gerou a revolução da IA
CUDA é a tecnologia de computação paralela da Nvidia, é usada por cientistas e engenheiros, e transforma sua GPU gamer num supercomputador.
![]() Carlos Cardoso 3 anos atrás
Carlos Cardoso 3 anos atrás
CUDA, que originalmente significava (em inglês) Arquitetura de Dispositivo Unificado de Computação, foi uma proposta da Nvidia que ninguém botou muita fé, mas rapidamente se tornou a melhor amiga dos cientistas, e hoje é a base da Inteligência Artificial que vemos por aí.
- Por que a Inteligência Artificial é tão ruim desenhando mãos?
- Whisper: Como usar IA para transcrever e traduzir áudios

Uma GeForce steampunk, because of reasons (Crédito: Stable Diffusion/Meio Bit)
Anunciada em 2006, a arquitetura CUDA teve seu primeiro SDK liberado em fevereiro de 2007. A primeira GPU compatível saiu em seguida. Em maio, a GeForce 8800 Ultra. Mas antes de explicar o que é CUDA, precisamos entender como uma CPU funciona.
A CPU, Unidade de Processamento Central é o “cérebro” do computador, mas ao contrário da maioria dos cérebros (excluindo comentaristas de portal e eleitores daquele cara) as CPUs não eram boas em fazer mais de uma coisa ao mesmo tempo.
Nos antigo ZX-81, e na versão nacional, o TK-82c, a CPU dividia seu tempo entre gerar a imagem e monitorar o teclado, era tão rápido que não dava para perceber, mas quando você mandava executar um programa, a interrupção de geração de vídeo era desabilitada e 100% de CPU era dedicada ao processamento.
Em todos os computadores da época, havia o conceito de interrupção por hardware, onde linhas do processador faziam com que o processamento fosse interrompido para que alguma tarefa fosse cumprida. Acima disso, num nível mais alto, tínhamos a execução dos programas em si, e somente um era executado de cada vez.
Simulação de ondas em tempo real usando CUDA. Em 2009. A empolgação era tanta que em 2008 tinha gente dizendo que CUDA seria o fim das CPUs.
Quando os processadores se tornaram mais poderosos, foi possível a chamada multitarefa cooperativa, onde um programa rodaria por algum tempo, então voluntariamente cederia ao sistema operacional o ponteiro de execução, permitindo que outro programa rodasse por uma fração de segundos. Assim, em teoria, vários programas seriam executados ao mesmo tempo.
Na prática era uma zona, um monte de programas se recusava a liberar a execução, uma travada em um significava travar geral. Bons tempos do Windows 3.1.
Somente com o Windows 95 veio a multitarefa preemptiva, onde o sistema operacional alocava uma fatia de tempo para cada programa, e controlava sua execução. Acabou o tempo, o programa era congelado e outro assumia o controle.
Para o usuário, várias coisas estavam acontecendo ao mesmo tempo, incluindo aquela ovelhinha maldita que andava pelo desktop, mas na prática era uma única CPU, executando uma instrução por vez, e dividindo seu tempo. Somente em 2002, com o Pentium 4 HT surgiram as threads, uma tecnologia que dividia virtualmente o núcleo da CPU em duas áreas de execução distintas, permitindo que instruções fossem executadas independentemente, de forma simultânea.

Pentium D (Crédito: Reprodução Internet)
Em 2005 veio o Pentium D, a primeira CPU com dois núcleos e quatro threads. Um jogo poderia rodar a 100% de CPU, enquanto um programa de comunicação baixava algo de um BBS, e outro programa encodava um MP3, e outra thread cuidaria do feijão com arroz do sistema operacional.
Hoje em dia a CPU comercial com maior capacidade é o Threadripper Pro 5995WX, um monstro com 64 núcleos e 128 threads, uma busca rápida no Mercado Livre diz que ele custa R$58.686. Se você for comprar um lote mande uma DM que eu passo o link de afiliado.
CPUs de gente normal ficam entre 6 e 8 núcleos, o que parece pouco, mas assim como 640KB é mais que suficiente para qualquer um. Os sistemas operacionais modernos são extremamente eficientes delegando tarefas, e a maioria dos programas não fica executando o tempo todo. Pense em quanto tempo o Word fica parado, enquanto você, digo, eu, enrola indo buscar café, checando o Twitter, olhando para a tela pensando no próximo exemplo depois de “checando o Twitter”.
Essa arquitetura permitiu algo que antes estava restrito a mainframes e supercomputadores: Computação paralela.
A maioria dos programas funciona de forma linear, um passo depois do outro, ele espera uma subrotina ser resolvida antes de partir pra próxima. Usando a velha analogia de trocar o pneu, primeiro coloca o macaco, ergue o carro, retira as porcas uma a uma, e então puxa o pneu.
Caso seu pneu tenha cinco porcas, você não precisa escrever o código para remover cada uma delas, você executa a mesma subrotina cinco vezes, mas em um programa convencional, ele executará cinco vezes, uma após a outra.
Em computação paralela você cria cinco instâncias da subrotina, atribui uma a cada porca, e manda executar todas ao mesmo tempo.
Existem muitos programas que se beneficiam de processamento paralelo. Processamento de imagem, por exemplo. Digamos que você quer reduzir o brilho de uma imagem com 50 Megapixels. Você pode usar um núcleo só, e percorrer todos os pixels, ou dividir o trabalho entre vários núcleos e threads, cara um tratando um pedaço da imagem. Como um pedaço não depende do outro, o trabalho pode ser dividido.
Processamento de vídeo é uma área que se beneficia muito com paralelismo. O FFMPEG, o melhor e mais versátil programa de manipulação de vídeo existente (se você souber usar linha de comando) usa e abusa de threads.
Podemos testar isso: Vamos usá-lo para converter um vídeo FULL HD 1920x1080 29.97fps de 7 minutos de duração para o formato H264. Primeiro vamos usar uma única thread, com o comando:
ffmpeg -hide_banner -loglevel quiet -stats -threads 1 -i teste.mp4 -c:v libx264 -threads 1 -stats testegpu_1_thread.mp4
Em um Ryzen 5 com 6 núcleos e 12 threads o processamento consumiu 18 minutos e 12 segundos. Já com as 12 threads alocadas para o FFMPEG, o tempo caiu para 2 minutos e 59 segundos.
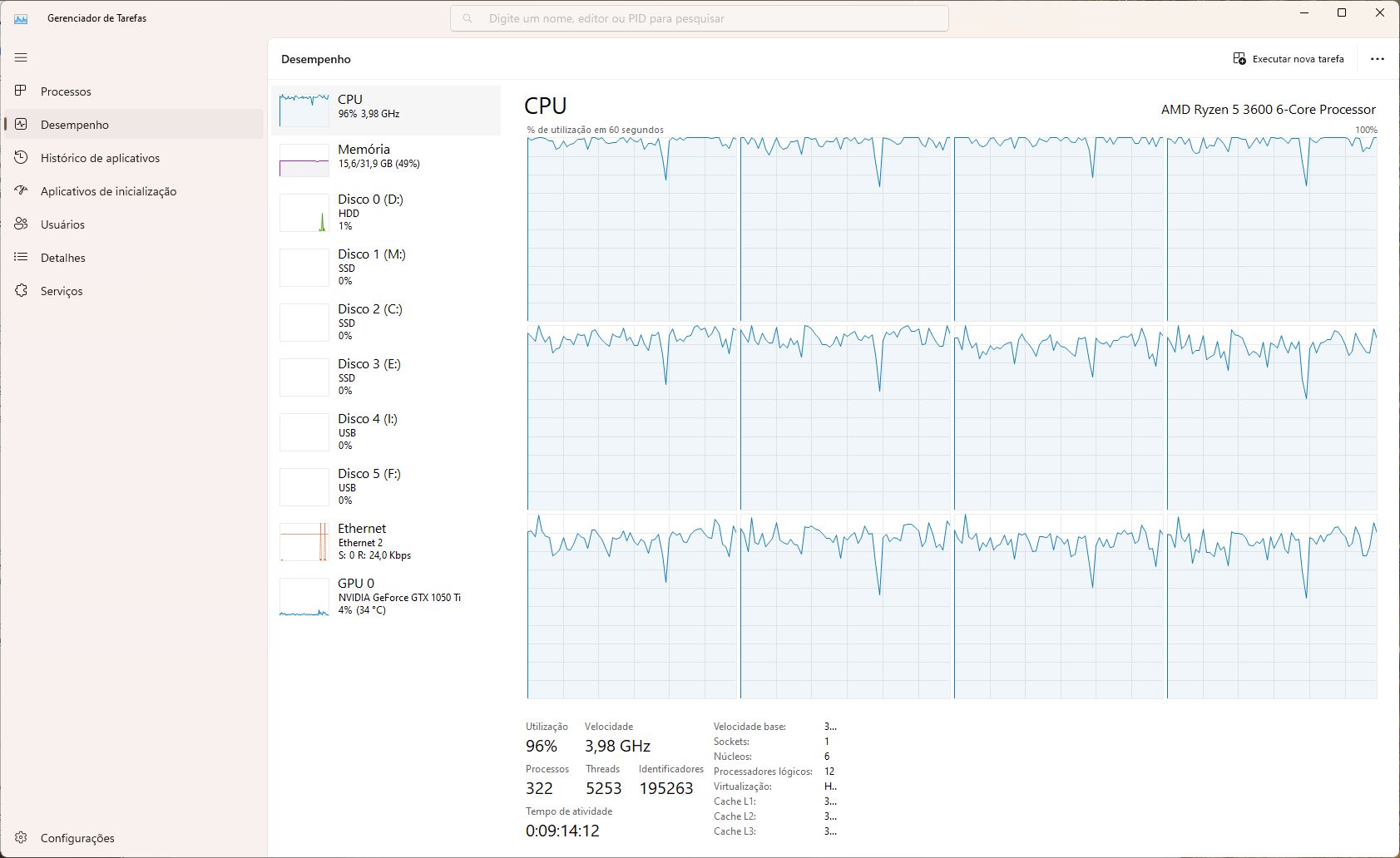
Mesmo assim é pauleira (Crédito: Meio Bit)
Mesmo assim ainda é demorado. Idealmente seria possível adicionar mais núcleos às CPUs, mas isso é muito caro e complexo, vide o Threadripper lá de cima.
Não que os gamers aceitassem isso como resposta. Eles queriam jogos mais bonitos, mais rápidos, e os fabricantes de GPUs tiveram uma idéia genial: Ao invés de CPUs, que tal criar pequenos módulos nos chips, de processamento dedicado, e um monte deles?
Um módulo especializado em colorir triângulos (o elemento básico dos gráficos 3D nas GPUs) não precisa de toda a complexidade de uma CPU completa, ele só sabe fazer uma coisa, mas bem rápido. Com um monte de módulos iguais, a GPU é capaz de desenhar e colorir milhões de triângulos por segundo.
Essa estratégia de criar módulos em hardware especializados tornou as GPUs bem mais flexíveis. Os chips da Nvidia trazem um encoder / decoder de vídeo, caprichado na computação paralela. Ele usa muito mais unidades para processar os arquivos, e deixa as CPUs comendo poeira.
Sabe o vídeo que levou 2min 59 segundos usando 12 threads de CPU? Se mandarmos o FFMPEG fazer a conversão, usando toda a CPU E o encoder via hardware da GPU, ele processa o arquivo inteiro em 42 segundos.
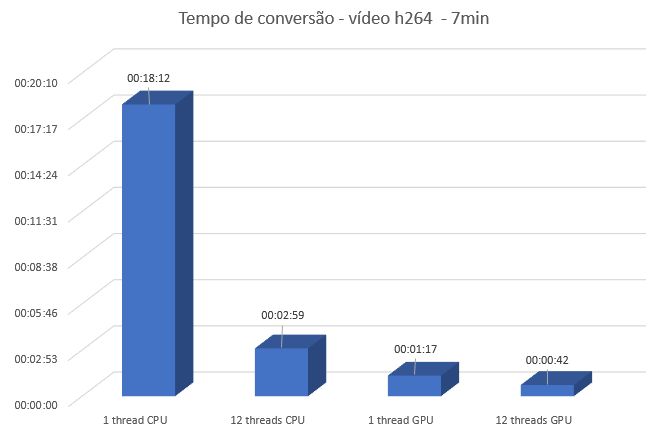
Tempo de conversão de arquivo (Crédito: Meio Bit)
Esses recursos de computação paralela estavam acessíveis via APIs gráficas, como DirectX, mas alguns programadores mais espertos começaram a usá-las para acelerar seus programas, pois os shaders e outros módulos basicamente trabalham com números, e se o resultado for o que você quer, não importa que esteja usando um módulo feito para desenhar triângulos.
Alguém na Nvidia viu que havia potencial, e redirecionou o desenvolvimento de GPUs, criando a arquitetura CUDA, onde centenas (a GeForce 8800 Ultra, uma das primeiras placas com suporte a CUDA vinha com 512 núcleos) de núcleos poderiam executar instruções em paralelo.
Ao contrário dos módulos como Shaders e Unidades de texturas, os núcleos CUDA foram projetados para executar muito rapidamente operações como álgebra linear, geração de números aleatórios, solucionadores de matrizes densas e esparsas, suporte à Performance Primitives (uma biblioteca da Intel para processamento de sinais e imagens) e, principalmente, os núcleos CUDA eram capazes de resolver a Transformada Rápida de Fourier.
Criada por Joseph Fourier (1768-1830), a Transformada de Fourier é uma ferramenta FUNDAMENTAL para... para basicamente tudo. Ela existe no MP3 que você ouve, cada vez que fala “Alexa” e ela responde, e em cada série que assiste.
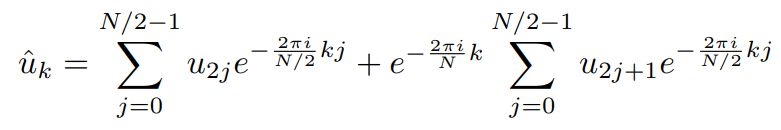
Como podemos ver, é bem simples (Crédito: Reprodução Internet)
Resumindo bem resumido, uma das versões dela, a Transformada Rápida de Fourier – descrita pela equação abaixo acima – permite que você decomponha um sinal em uma série de linhas senoidais. Assim uma música pode ser descrita como uma série de curvas, traduzidas para números, ocupando bem menos espaço do que o sinal original completo, mas dependendo da precisão utilizada, indistinguível do original.
Toda uma área de programadores não-gamers começou a se interessar pela tecnologia CUDA, os ganhos de processamento eram incontestáveis. É fácil de determinar isso. Vamos executar uma Transformada Rápida de Fourier em um array de 100 milhões de números.
Primeiro, vamos criar o tal array, usando este script em Python:
import random
# Define a quantidade de números a gerar
num_inteiros = 100_000_000
# Gera os números e salva no arquivo
with open('random_inteiros_100M.txt', 'w') as f:
for i in range(num_inteiros):
# gera um número aleatório entre 0 e 255
rand_int = random.randint(0, 255)
# Escreve o número no arquivo
f.write(f"{rand_int},")
O arquivo resultante tem uns 300MB de tamanho. Vamos agora executar um script para aplicar a TTF em cada um dos 100 milhões de números:
import time
import numpy as np
# Lê o arquivo e joga em um array do numpy
with open('random_inteiros_100M.txt', 'r') as f:
data = np.array(f.read().split(',')[:-1], dtype=np.int32)
inicio = time.time()
# Aplica a transformada usando a função FFT do numpy
fft_resultado = np.fft.fft(data)
# Imprime o resultado
print(fft_resultado)
fim = time.time()
print(f"Tempo de Execução: {fim - inicio} segundos")
Este programa mostra como as linguagens e CPUs estão eficientes. No meu PC ele rodou em apenas 4 segundos. Mas podemos fazer melhor:
Vamos usar este script agora:
import time
import cupy as cp
import numpy as np
# Lê o arquivo e joga em um array do numpy
with open('random_inteiros_100M.txt', 'r') as f:
data = np.array(f.read().split(',')[:-1], dtype=np.float32)
# Transfere o array para a GPU
data_gpu = cp.asarray(data)
inicio = time.time()
# Aplica a transformada usando CuPy
fft_resultado_gpu = cp.fft.fft(data_gpu)
# Transfere o resultado de volta para a CPU
fft_resultado_cpu = cp.asnumpy(fft_resultado_gpu)
# imprime o resultado
print(fft_resultado_cpu)
fim = time.time()
print(f"Tempo de Execução: {fim - inicio} segundos")
Ele joga o array para a GPU e usa CUDA para aplicar a Tranformada Rápida de Fourier, usando os 768 núcleos ao mesmo tempo.
O resultado? O tempo de execução cai para 0.93 segundos.
Aqui um pequeno parêntese: Veja o gráfico:
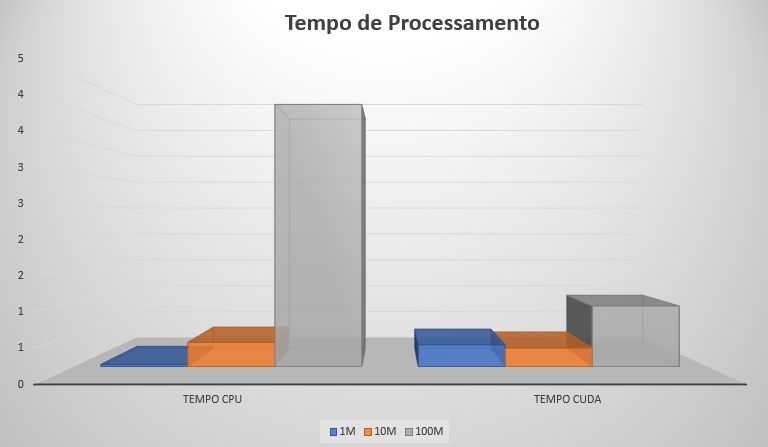
Tempo de execução (Crédito: Meio Bit)
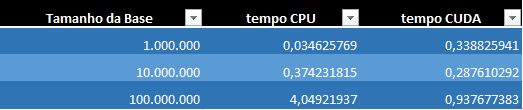
Tempo de execução (Crédito: Meio Bit)
Nem sempre CUDA é a solução mais rápida. Com dez milhões de números, a GPU é somente um pouco mais rápida, e com apenas um milhão, a CPU ganha, pois não precisa passar pelo processo de enviar e receber os dados da GPU.
Nota: Esses resultados impressionantes foram obtidos com uma GPU lançada em 2016, que nunca foi high-end.
Essa capacidade de lidar com cálculos em quantidades obscenas tornou CUDA extremamente atraente para simulações, dinâmica de fluídos, CAD, biologia, design de proteínas e moléculas complexas e muito mais.
CUDA e IA
Inteligência Artificial é um nome que os marqueteiros das universidades inventaram para conseguir verbas, é muito mais sexy do que álgebra linear aplicada, mas essencialmente o que a gente chama de IA são bilhões de contas envolvendo matrizes com milhares de dimensões. É apenas matemática, matemática simples e repetitiva. E CUDA é perfeito pra isso.

Esta imagem, 512x512 levou 43 segundos para ser gerada via GPU/CUDA em uma GeForce 1050 Ti com 4 GB de VRAM. Usando uma CPU AMD Ryzen Threadripper 1900X, ela levaria 2 minutos e 58 segundos para ser criada (Crédito: Meio Bit)
O Stable Diffusion trabalha com modelos com 859,52 milhões de parâmetros, arranjados em uma matriz de complexidade insana. Uma CPU trabalhar linearmente, ou no máximo com algumas threads é um pesadelo. Já uma GPU consegue paralelizar esse processamento, atribuindo a cada núcleo CUDA uma parte do problema. Por isso aplicações IA são um foguete em uma RTX 4090, com 16.384 núcleos CUDA.
Claro, se você tiver dinheiro sobrando pode comprar uma H100, solução da Nvidia para data centres. São 16896 núcleos CUDA, 80GB de VRAM e consumo de 700w.

Nvidia H100. Não é pro nosso bico mas é danada de bonita (Crédito: Nvidia)
A aposta da Nvidia rendeu frutos, hoje CUDA é basicamente o padrão entre cientistas, pesquisadores, engenheiros e maníacos por waifus geradas por IA. As GPUs que sumiram por causa da onda das criptomoedas agora estão sendo cobiçadas pelo povo da IA, e só não vão escassear porque a maioria dos programas não faz uso de mais de uma GPU ao mesmo tempo.
Como dica final: Se você planeja um upgrade de placa de vídeo, priorize VRAM. As aplicações em IA (e jogos também) precisam de bastante memória. Há gargalos o bastante para não haver tanta diferença entre uma GPU e outra ligeiramente mais cara, mas memória determinará se você poderá ou não executar recursos mais complexos, como treinar modelos, Textual Inversions e LORAs.
De resto, parabéns à Nvidia por ter tido a visão de investir em uma tecnologia tão revolucionária.


