Flux: as mais avançadas imagens de IA no seu PC
Flux é o mais novo modelo de geração de imagens IA, disponível para baixar e rodar em casa, sem censura e com inúmeros recursos avançados. Confira neste tutorial!
![]() Carlos Cardoso 2 anos atrás
Carlos Cardoso 2 anos atrás
Flux é algo que ao contrário da Inquisição Espanhola, todo mundo esperava, mas não tão cedo, não tão bom. É, sem sombra de dúvida, o modelo open source de geração de imagens mais avançado do momento, brigando pau a pau, ou mais precisamente mano a mano com ferramentas tipo DALL-E e Midjourney.

Crédito: Flux
O Flux foi criado pela Black Forest Labs, uma startup de IA fundada por ex-membros da Stability AI, criadora do Stable Diffusion, e lançado dia 1º de agosto de 2024, sem aviso, apenas soltaram a bomba. E meninos e meninas, que bomba!
(nota: Os prompts estão traduzidos, mas foram introduzidos (epa!) originalmente em inglês)

Prompt usado: "Um personagem de desenho animado em forma de bomba da Segunda Guerra Mundial, andando, segurando um pincel desenhando em uma tela a palavra "MeioBit" em fonte multicolorida, cenário de fantasia" (Crédito: Flux)
Cinco meses antes a Stability AI lançou o Stable Diffusion 3, um modelo promissor, mas que não diferia muito do Stable DiffusionXL, e acabou decepcionando muita gente. As ferramentas de facto para o povo que gera imagens em casa continuaram sendo o Stable Diffusion 1.5 e o SDXL, ambos com um excelente conjunto de acessórios, como ControlNets, IP Adapters, LORAs e similares. Por isso o ceticismo quando o Flux apareceu.

Prompt: Superman, Batman e Mulher-Maravilha na sede da Liga da Justiça, observando um monitor de parede gigante exibindo as palavras PERIGO: FLUXO! a tela está cheia de dados de computador, gráficos e tabelas, uma luz gigante de alerta vermelha no teto ilumina a sala com um brilho vermelho (Crédito: Flux)
Flux: Primeiras impressões
A Black Forest Labs espertamente disponibilizou vários parceiros onde era possível testar o Flux, sem precisar instalar localmente, e os primeiros resultados foram avassaladores. O Flux é superior a tudo que a Stability AI já produziu, especialmente em alguns pontos:
1 – Aderência ao Prompt
Normalmente precisamos de várias tentativas até conseguir que o Stable Diffusion gere a imagem de acordo com o prompt. Ele costuma “esquecer” um ou outro elemento, ignorando ou alterando outros, às vezes misturando conceitos. Em cenas complexas isso é trabalhoso, temos que usar recursos como inpainting e IP Adapters para induzir a IA a produzir exatamente o que queremos.

Prompt: James Bond vestindo um smoking em um cassino. Sentado em seu ombro esquerdo há um homem em miniatura vestido como o diabo, com forcado e terno vermelho. Sentada em seu ombro direito, uma mulher em miniatura vestida como um anjo, roupas longas, auréola brilhante, segurando uma harpa. James Bond está segurando uma pequena pistola em posição de alerta, ele está usando os óculos de Elton John. Os óculos são coloridos, escandalosos e brilhantes (Crédito: Flux)
No caso do Flux ele tem um interpretador muito mais poderoso, “traduzindo” o prompt em tokens internos de forma muito mais eficiente. Ele consegue entender muito melhor o que o autor do prompt quer que ele desenhe.
Mais ainda; ele entende linguagem natural, não é preciso mais usar tags e macetes como (((decote))) ou escamas:3 para enfatizar detalhes. Você pode apenas descrever em detalhes meticulosos o que quer desenhar. E se faltar imaginação, pode pedir ao ChatGPT para descrever para você, e copiar o prompt.
Essa aderência do Flux permite uma capacidade de composição de cena inigualável, mesmo comparando com ferramentas tipo Midjourney, e não pára aí.
2 – Prompts complexos
Se você achou o Bond aí de cima complexo, veja esta imagem, que roubei do Reddit. Ao lado dela, o (gigantesco) prompt.
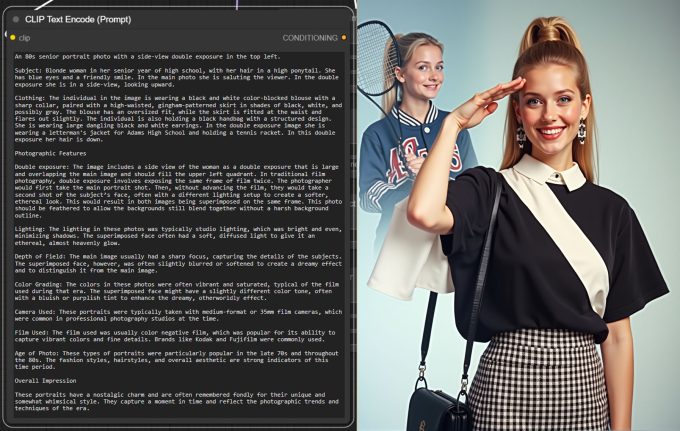
Crédito: Flux
Você pode detalhar sua imagem até o ponto em que precise de ajuda psiquiátrica para controlar sua obsessão. O Flux de vez em quando vai cometer um errinho ou outro, mas no geral sua imagem incrivelmente complexa e detalhada será produzida seguindo seu prompt.
3 – Mão é Mão, paca é paca!
Todo mundo do meio sabia que o problema das IAs com mãos era transitório, mas ninguém imaginou que seria resolvido tão rápido. Nenhuma das imagens acima sofreu qualquer retoque. O Flux tem uma taxa de acerto altíssima em se tratando de mãos, mesmo em situações complexas.

Prompt: Uma mão feminina segurando uma maçã. A maçã é brilhante e perfeita com uma única folha verde, há um reflexo de uma janela na maçã. A mão é jovem, impecável, as unhas são longas e pintadas com esmalte roxo brilhante. Ela está usando um anel de ouro (Crédito: Flux)

Prompt: foto de uma mão feminina segurando uma bolha de sabão entre o polegar e o indicador, o pulso é adornado por uma corrente de prata ornamentada com pequenas pedras preciosas. A mão tem unhas verdes longas e bem cuidadas (Crédito: Flux)
Ele também entende e faz bem pés e poses impossíveis para o SD3, como pessoas deitadas de bruços na grama.
Claro, o Flux não é perfeito. Desenhar mãos é algo complicado mesmo para humanos. Neste artigo aqui, expliquei o motivo dessa dificuldade. Em resumo, a IA não entende o conceito de “mão”, e a quantidade de amostras usadas para seu treinamento não é suficiente para que a maioria das variações quase infinitas de posições de dedos seja aprendida.
Mesmo assim, o Flux tem uma taxa de acerto altíssima, mãos ruins deixam de ser regra e viram exceção.
4 – Texto no Flux é show

Prompt: seven cute cartoon animals side by side, each one with a t-shirt with a letter, the letters form the word "MeioBit" (Crédito: Flux)

Prompt: "photo of a student's notebook, open with a text handwritten with a ballpoint pen, the text says "IA nunca vai conseguir fazer texto direito." a female hand is holding a pen, close to the notebook" (Crédito: Flux)
A primeira versão do Stable Diffusion eram incapaz de criar texto coerente. A SDXL era melhorzinha. A 3 até quebrava o galho com palavras curtas. Online o DALL-E 3 era um modelo com boa capacidade para texto, mas estamos falando de modelos rodando em datacentres. Localmente não havia nada que chegasse aos pés dele.
Até o Flux. Ele não só é excelente com texto, a aderência ao prompt e a capacidade de entender o contexto faz com que imagens complexas como a dos bichinhos acima seja prontamente compreendida. Sem mentira, essa foi a primeira tentativa.
O texto do caderno demorou mais, o Flux precisou de várias tentativas até acertar, mas isso é preciosismo. No mundo real a gente escolheria a versão mais adequada e corrigiria no Photoshop.

Prompt: foto da supergirl em um café, tomando um milkshake. Na parede um letreiro neon azul com os dizeres "O Céu é o Limite" (saiu de primeira) (Crédito: Flux)
5 – O Flux é poliglota!
O Flux usa um LLM (Large Language Model) bem decente para traduzir os prompts para sua linguagem interna de tokens, e esse LLM é treinado em vários idiomas. O Flux fala inglês, alemão, romeno, francês, espanhol e até português. A imagem da Supergirl acima foi gerada com o prompt 100% em português.
Aviso: Os resultados não são consistentes, o prompt em inglês produz resultados melhores, especialmente em casos de prompts mais complexos, mas é bom que a possibilidade de fazer prompts simples na Última Flor do Lácio exista.
Flux: Como instalar
O Flux é muito bom, mas o que ele tem de bom, tem de pesado. Já é um milagre ele rodar em hardware para consumidor final, ie Gamers. Isso quer dizer que não vai rodar na maioria dos PCs.
Há uns malucos que conseguiram rodar o Flux com 4GB de VRAM, mas sendo prático, dificilmente você conseguirá um desempenho minimamente aceitável com menos de 8GB de VRAM, e uns 16GB de RAM. Ah sim, sua GPU tem que ser Nvidia. Se você for Team Red, game over.
No meu caso, uso uma GeForce 3060 com 12GB de VRAM e 64GB de RAM. Consigo gerar uma imagem 1024x1024 no Flux em mais ou menos um minuto e meio.
A melhor interface para usar o Flux é o ComfyUI, mas ele tem uma curva de aprendizado meio cruel, e sendo honesto, é bem assustador para novatos. Eu compreendo que pessoas normais olhem um workflow desses e saiam correndo.
A alternativa é o Forge, um fork do AUTOMATIC1111, ele é voltado para iniciantes, pode ser bem complexo se você quiser, ou funcionar quase na base do next-next-next. Com a vantagem de ter todas as aplicações necessárias, como GIT, Python, PIP no mesmo pacote.
Passo 1 – Download
Acesse este site do GitHub e baixe a última versão do Forge. É recomendado que você escolha a webui_forge_cu121_torch231.7z, é a mais estável.
Crie uma pasta no seu disco C: chamada FORGE, e salve o arquivo de 1.74GB nele.
Usando o Winrar ou outro descompactador de arquivos se sua preferência descompacte o webui_forge_cu121_torch231.7z. O resultado deve ser uma organização de pastas assim:
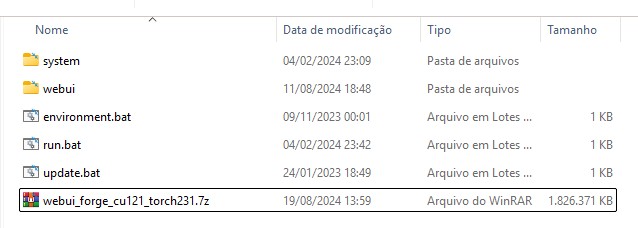
Agora você pode apagar o arquivo .7z e liberar espaço em disco, você vai precisar.
Passo 2 – Atualizar
Com um duplo-clique, execute sem dó o arquivo update.bat.
*CABUM* você foi interrompido por uma tela de alerta, avisando que coisas horríveis podem acontecer se você executar esse arquivo. Confie em mim, clique em mais informações e selecione Executar Assim Mesmo.
Calma
Ele irá acessar o repositório do Forge no GitHub e baixar a versão mais recente. Rapidamente, pedirá para você apertar qualquer tecla, e a janela de terminal se fechará.
Passo 3 – Rodar
Duplo-clique em run.bat, você receberá de novo o alerta assustador. De novo, clique em mais informações e execute mesmo assim.
Agora o Forge irá instalar as dependências, os módulos do Python necessários para rodar a aplicação, e baixará um checkpoint do Stable Diffusion 1.5. Se tudo der certo, ao final ele abrirá uma janela do seu navegador com a interface do Forge.
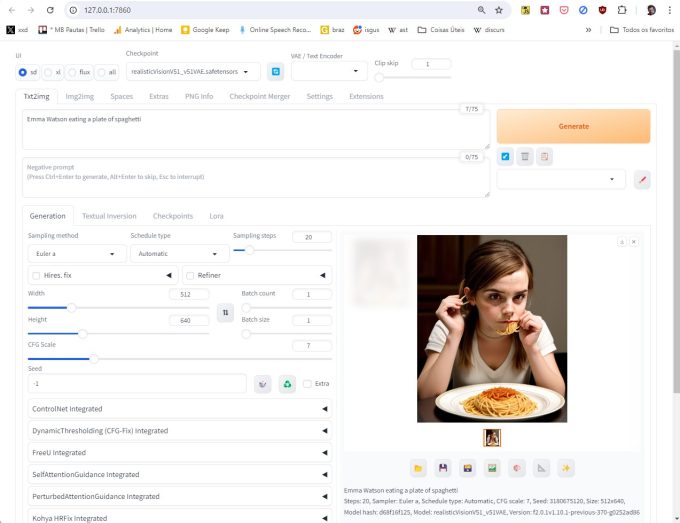
Interface do Forge
No campo do prompt, digite algo como “Emma Watson eating a plate of spaghetti” e clique em Generate. Se tudo der certo, em alguns segundos você terá uma imagem.
Ou dezenas, só escolher no slider Batch Count quantas imagens você quer gerar.
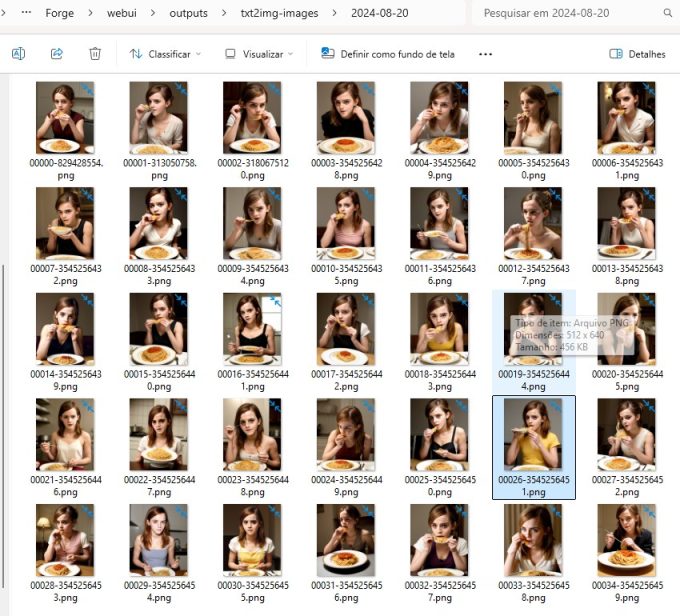
Ah sim, na nossa instalação as imagens são salvas na pasta:
C:\Forge\webui\outputs\txt2img-images
Passo 4 – E o Flux?
Você não chegou até aqui para usar o SD1.5, obviamente. Vamos então para o prato principal: Primeiro, baixe o checkpoint do Flux. Não a versão com 23GB, isso é forçar a amizade. A Comunidade produziu versões quantizadas com excelente quantidade e metade do tamanho.
Neste link do Huggingface, baixe o arquivo flux1-dev-bnb-nf4-v2.safetensors, são apenas 12GB.
Enquanto está baixando, vá na pasta:
C:\Forge\webui\models\Stable-diffusion\
Crie uma pasta chamada FLUX dentro dela, o caminho agora será:
C:\Forge\webui\models\Stable-diffusion\FLUX
É nesta pasta que você deve colocar o flux1-dev-bnb-nf4-v2.safetensors, depois que ele terminar de baixar.
Agora clique no alto da interface, canto esquerdo, selecione a UI “Flux”. Do lado, selecione o checkpoint FLUX\ flux1-dev-bnb-nf4-v2.safetensors. Caso ele não apareça, clique no ícone de refresh e tente de novo.
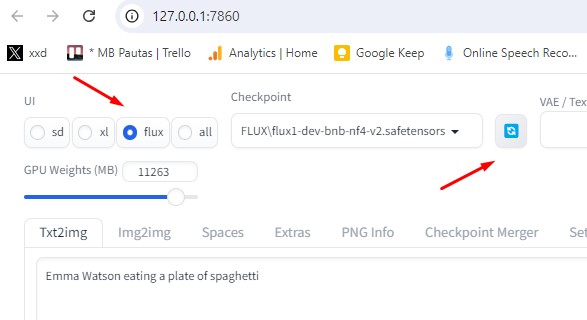
Clique aqui
Agora é só escrever seu prompt, e mandar gerar a imagem. Vai demorar bem mais. No meu caso, com a resolução default do Forge para Flux, 896 x 1152, uma imagem leva aproximadamente 1’15” para ser gerada.
Você pode usar os controles de resolução para diminuir ou aumentar o tamanho da imagem a ser gerada, mas não vá muito além de 1200x1200. O ideal é 1024x1024, ou até menos, 512x512, quando você estiver experimentando com prompts. Quanto menor a imagem, mais rápido será gerada.
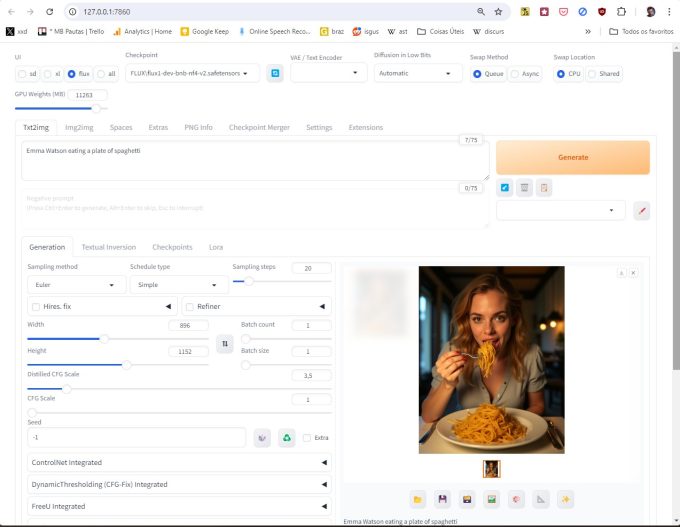
Note a ligeira diferença de qualidade entre o SD1.5 e o Flux
Qual o segredo do Flux?
Complexidade. Quanto mais complexa a rede neural, mais interações são possíveis entre os nós, essa complexidade determina quantos parâmetros são analisados para a geração da imagem. No Stable Diffusion 1.5, a rede neural tinha 890 milhões de parâmetros. O SDXL comporta 2.3 bilhões de parâmetros, e a qualidade já era bem superior.
O Flux opera com 12 bilhões de parâmetros, essa complexidade por si só resolveu vários dos problemas que afligiam as versões anteriores. Agora imagine em alguns anos, redes com 100, 200 bilhões de parâmetros, o que serão capazes de criar!
Conclusão
No próximo artigo ensinarei técnicas de prompt, composição e como usar LLMs para refinar e aprimorar suas imagens, bem como ferramentas e extensões do Forge.
Por enquanto, divirta-se com o Flux.



