Whisper: Como usar IA para transcrever e traduzir áudios
Whisper é uma aplicação de IA para transcrever e traduzir áudios para arquivos em texto, e é apenas sensacional para profissionais da escrita
![]() Carlos Cardoso 1 ano e meio atrás
Carlos Cardoso 1 ano e meio atrás
Antes de chegar no Whisper, vamos situar o problema: Transcrever áudios e decupar vídeos estão entre os maiores trabalhos de corno do jornalismo, é algo universalmente odiado. Muito. Nem a Dona Solange, do tempo da Ditadura era tão odiada pelo povo das redações.
- Transcrições de vídeos usando IA para busca de palavras
- Dica Master MacGyver: usando o Google Docs para transcrever áudio!

Meh. (Crédito: Stable Diffusion)
Quando um repórter volta de uma entrevista, com seu gravador lotado de declarações suculentas, ele tem que sentar o traseiro na cadeira, abrir o arquivo no computador e pacientemente transcrever todas as perguntas e respostas. É um trabalho enorme, cansativo, repetitivo e que sobra pros estagiários.
A turma do vídeo tem que fazer a mesma coisa, marcando as partes importantes, transcrevendo os diálogos e anotando o ponto em que eles acontecem. Um dos maiores fatores que tornava complicado a produção de episódios do Top Gear, e depois do Grand Tour, é que os produtores acabavam com centenas de horas de gravações, com diversas câmeras, e tudo precisava ser transcrito, manualmente.

Transcrição das conversas em uma filmagem do Grand Tour (Crédito: Mr Wilman)
Povo dos podcasts, que sempre quis disponibilizar uma versão em texto, esta é a ferramenta ideal.
Hoje existem vários serviços, a maioria pagos, que se propõe a fazer esse tipo de trabalho, mas as transcrições não costumam sair boas, são sensíveis a ruído, e poucos serviços funcionam em português.
Isso não vem de hoje, muitos anos atrás o mercado era dividido entre o IBM Via Voice e o Dragon Dictate, dois softwares especializados em reconhecimento de voz. O Via Voice vinha com um microfone especialmente calibrado, e não funcionava com outro. O Dragon Dictate exigia que você lesse dezenas de páginas para que ele aprendesse a reconhecer sua voz.
Eram aplicações primitivas, do tempo em que falar com computador era coisa de ficção científica.

Falar com computador? Só será normal no Século XXIII (Crédito: Paramount Pictures)
Hoje aplicativos como o Word e sistemas como o Android e o iOS já vem com ferramentas de ditado, mas transcrição de texto ainda é complicado. Ou era! Seus problemas acabaram, amigo jornalista! Com o Whisper você nunca mais vai passar horas decupando aquela maldita entrevista.
Afinal, o que é o Whisper?
Segundo o GPT-4:
“Whisper é um sistema de reconhecimento de fala automático (ASR) baseado em inteligência artificial que foi treinado e é disponibilizado pela OpenAI1. Whisper é capaz de transcrever áudio em texto com alta precisão e robustez, mesmo em condições desafiadoras como sotaques, ruídos de fundo e linguagem técnica. Além disso, Whisper pode transcrever áudio em vários idiomas e também traduzir esses idiomas para o inglês.”
Quase. Além de traduzir para o inglês o Whisper também traduz para outros idiomas. Ele tem capacidade inclusive de fazer isso em tempo real, você fala em português no seu microfone, o texto aparece na tela em japonês. Mas não vamos colocar a carroça adiante dos bois.
Você está aqui para se livrar da decupagem, eu entendo. A boa notícia é que em 2022 a OpenAI abriu o código-fonte do Whisper, e mais tarde liberou os modelos treinados, que são a parte mais cara e inacessíveis dessas redes neurais. Com isso surgiram várias implementações. Uma das mais populares é obra de um programador búlgaro chamado Georgi Gerganov.
Ele tem um repositório bem popular no GitHub, e seu port do Whisper é excelente, com versões pra Mac, PC e até Android.
Uma das limitações da versão de Georgi acaba se tornando uma vantagem: Ela roda somente em CPU, o que significa que você não precisa se preocupar com o modelo da sua GPU, instalar CUDA, Pytorch e outras partes mais cabeludas dessa informática de raiz.
O que dá pra fazer com o Whisper?
Entre outras possibilidades:
- Transcrever para texto um arquivo em áudio
- Transcrever para texto em um idioma um arquivo em áudio em outro idioma
- Criar um arquivo .srt de legendas com base em um áudio
- Criar um arquivo .srt de legendas traduzidas com base em um áudio
- Implementar um assistente de voz rodando no seu PC
- Transcrever áudio em tempo real direto do microfone
- Transcrever e traduzir áudio em tempo real direto do microfone
No nosso caso, vamos instalar o Whisper e aprender a converter um arquivo de áudio em português em um texto editável. Mais ou menos como este vídeo:
Este tutorial está dividido em 7 partes:
- Instalação dos Pré-requisitos
- Download do Whisper
- Download dos modelos
- Conversão do áudio
- Uso básico
- Configurações extras
- Bônus: GPU
Para baixar o vídeo de exempplo você pode usar os vários serviços online que fazem downloads de vídeos do YouTube. Eu prefiro usar o Jdownloader 2, um programa especializado em baixar arquivos de sites não-cooperativos, mas você pode usar qualquer arquivo de vídeo ou áudio que tiver disponível para o teste. Ou você pode usar o Audacity e gravar um áudio falando alguma coisa, tanto faz.
OK, vamos começar. Primeiro de tudo, crie uma pasta WHISPER na raiz do seu drive C: Deixe-a quieta, depois voltamos. Agora é hora dos...
1 – Whisper – Pré-requisitos
Essa é a melhor parte: O Whisper não tem quase nenhum pré-requisito. A única coisa que ele precisa é dos arquivos de áudio em formato .WAV 16 bits. Para isso é recomendado converter usando o FFMPEG, um programa em linha de comando maravilhoso para fazer tudo que você puder imaginar com áudio e vídeo. Ele será usado para converter arquivos MP4 e MP3 em WAV.
Para instalar o FFMPEG são necessários alguns passos simples:
- Crie um diretório FFMPEG na raiz do seu disco C:
- Acesse o repositório e baixe o arquivo ffmpeg-master-latest-win64-gpl.zip
- Descompacte o conteúdo do arquivo no diretório C:\FFMPEG. Cuidado para não criar pastas extras, as pastas bin e doc devem ficar logo abaixo da FFMPEG, em C:\FFMPEG\bin
- Na janela de pesquisa do Windows, digite “prompt de comando” e selecione a opção “Executar como Administrador”
- No prompt, digite: setx path "%path%;C:\ffmpeg\bin" /m
- Se a mensagem de que o valor especificado foi salvo for exibida, feche a janela, e reinicie seu computador.
- Abra uma janela de prompt de comando normal e digite ffmpeg -version
- Caso a instalação tenha sido bem-sucedida, você verá uma tela parecida com esta:
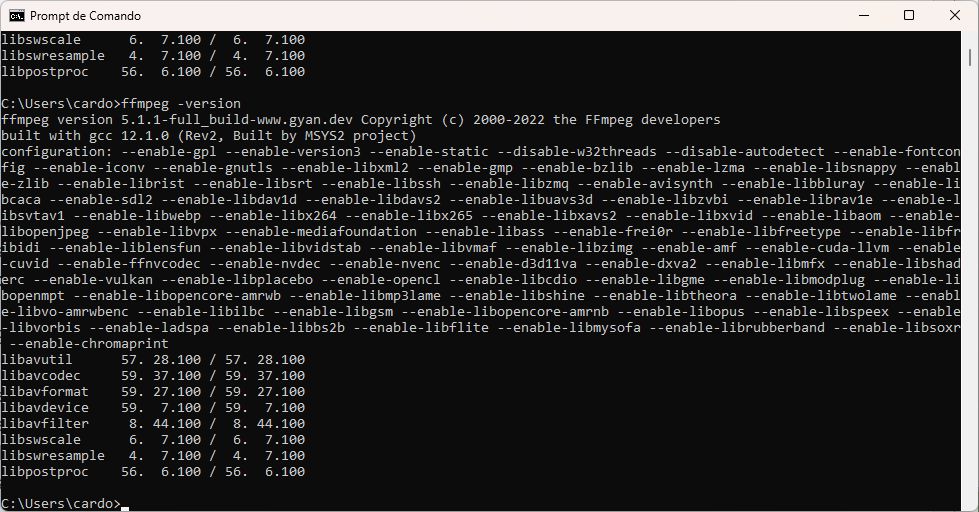
FFMPEG instalado com sucesso. (Crédio: Meiobit)
2 – Download do Whisper
Vá até o repositório no GitHub, selecione o link da última versão, este aqui. Desça até a seção Assets e baixe o arquivo whisper-bin-x64.zip, descompacte-o na pasta C:\WHISPER
Minúsculo, né? Mas agora precisamos baixar os modelos treinados, o firmware que faz o cérebro da Inteligência Artificial funcionar. Diga para seu roteador se preparar, pois hoje você vai lhe usar.
3 – Download dos Modelos
Acesse esta página do Hugging Face, um dos principais sites do mundo sobre tudo que diz respeito a IA.
Repare que ao lado do ícone LSF em cada arquivo, há uma setinha. É um atalho de download. Você baixar os seguintes arquivos:
- ggml-base.bin
- ggml-large.bin
- ggml-medium.bin
- ggml-small.bin
- ggml-tiny.bin
Eles vão do minúsculo tiny com 77MB ao monstruoso large, com 3GB. (eu falei que você ia usar o roteador).
Mova os arquivos para a pasta C:\WHISPER.
4 – Conversão do Áudio
Lembra do arquivo getulio.mp4 que você baixou, o arquivo de áudio que gravou? Vamos convertê-lo para o formato que o Whisper gosta.
Abra um prompt de comando, e vá para o diretório, só digitar "cd C:\Whisper" (você sabe que tem que apertar <ENTER> depois dos comandos, certo, Pequeno Gafanhoto?).
No diretório C:\whisper, você vai digitar o seguinte comando:
ffmpeg -i getulio.mp4 -ar 16000 -ac 1 -c:a pcm_s16le getulio.wav
isso vai criar um arquivo chamado getulio.wav, e estamos prontos.
5 – uso básico
Na mesma janela de comando, digite:
main -f getulio.wav -l portuguese -m ggml-small.bin
Se tudo der certo, ele irá carregar o modelo em memória e iniciar a transcrição. No final você acabará com uma tela parecida com esta:
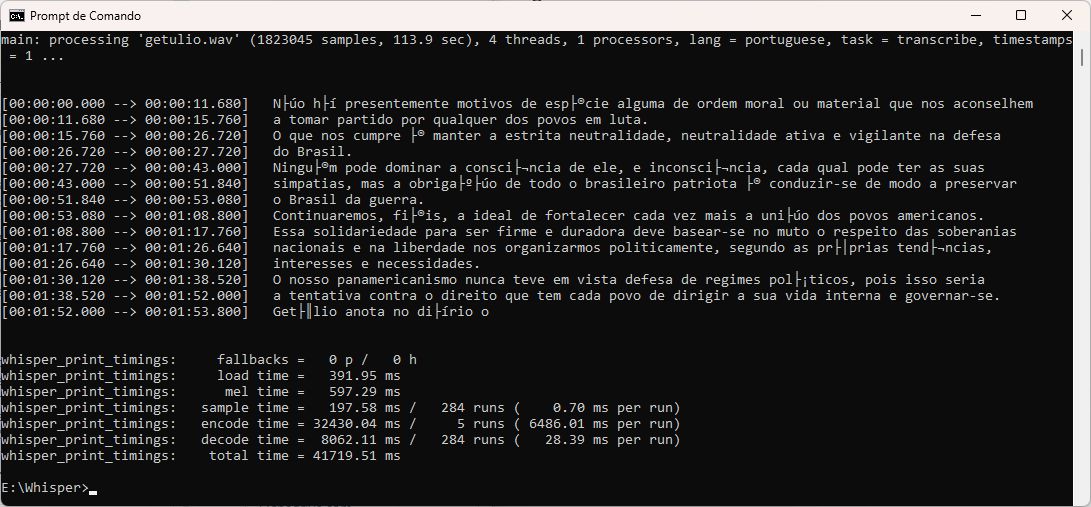
Bela postura... deu sertinho. (Crédito: Meiobit)
Claro, assim o texto não ajuda muito. Vamos acrescentar dois modificadores à nossa linha de comando:
main -f getulio.wav -l portuguese -m ggml-small.bin --output-txt --output-file getulio
--output-txt indica que o Whisper deve gerar um arquivo em formato texto.
--output-file é o nome do arquivo, sem extensão, pois ele cuidará de acrescentar o .txt
Com esses modificadores, o resultado é um arquivo com nosso texto, devidamente transcrito.
Note que como não estamos na Idade das Trevas, a acentuação funciona perfeitamente.
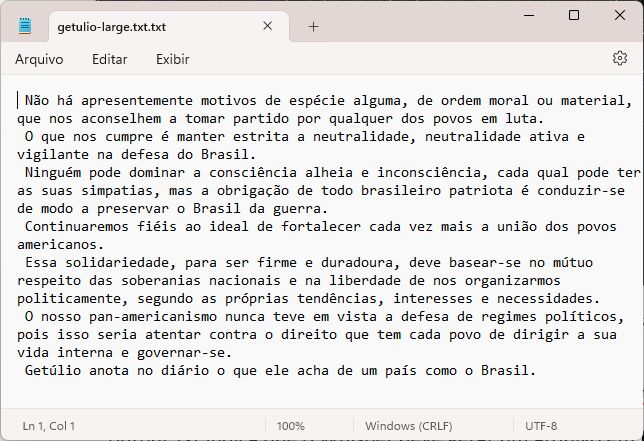
Tudinho com acento correto. (Crédito: meiobit)
Simples assim: No diretório do Whisper, rode o comando:
main -f <arquivo em formato WAV> -l portuguese -m ggml-medium.bin --output-txt --output-file <nome do arquivo texto>
O tempo de processamento vai depender do tamanho do modelo e da duração do arquivo de áudio. No nosso exemplo getulio.wav tem 1’33”. É convertido em meu Ryzen 5 3600 em 2.2 minutos. Não é maravilhoso mas bem melhor do que digitar. Dá pra melhorar? Aguarde as cenas dos próximos capítulos.
6 – Configurações extras
Minha CPU tem 6 núcleos, é capaz de executar 2 threads em cada um deles, num total de 12. O default do Whisper usa 4 threads. Com o comando -t n, onde n é o número de threads, podemos dedicar mais recursos da CPU.
Para saber o número de threads em sua CPU, basta olhar na janela do prompt de comando depois que iniciar o Whisper, há uma linha assim:
system_info: n_threads = 4 / 12 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 0 | NEON = 0 | ARM_FMA = 0 | F16C = 0 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 0 | VSX = 0 |
O tempo de execução cai razoavelmente.
--speed-up
Adicionando esse parâmetro na linha de comando, o áudio será “ouvido” pela IA acelerado em 2 vezes a velocidade normal. Isso pode acarretar perda de precisão, mas se for um áudio bem limpo, de boa qualidade, pode dar bom resultado.
--nt
Exibe a transcrição sem as marcações de tempo, produzindo texto corrido, assim:
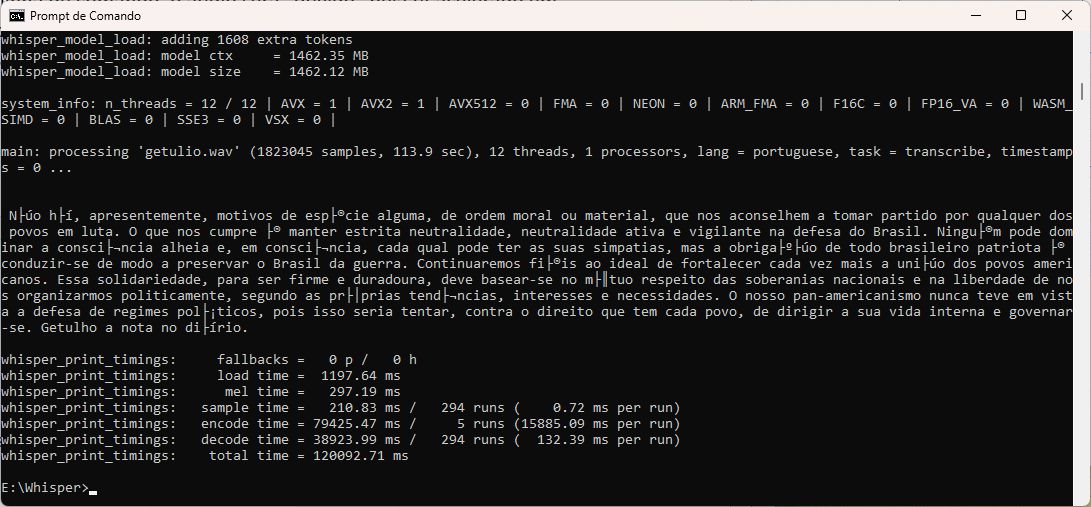
Textinho corrido pra ler de carreirinha como o Zeca Diabo. (Crédito: Meiobit)
--output-srt
Esse o povo vai adorar. Em conjunto com o --output-file <nome do arquivo> ele gera um arquivo de legenda, formato .srt, com a transcrição/tradução do áudio. Em segundos, temos uma legenda plenamente funcional:

O VLC carregou automaticamente, até. (Crédito: Meiobit)
-pp
É o comando Print Progress, ele irá dar um percentual de progresso da transcrição, especialmente útil no caso de arquivos longos.
Existem vários outros comandos e modificadores, mas fogem do escopo de um tutorial para iniciantes, e eu também não tenho ideia do que eles fazem.
7 – Bônus – GPU
OK, digamos que você tem preguiça de usar linha de comando, e por acaso tem uma GPU decente, e por decente eu digo qualquer coisa igual ou superior à minha ancestral GeForce 1050TI com 4GB de VRAM.
Neste caso, boas novas! Há uma GUI, que não é escrita em Visual Basic nem rastreia IPs, mas torna mais simples ainda o uso do Whisper.
Vá neste repositório aqui, e baixe o arquivo WhisperDesktop.zip.
Crie uma pasta chamada dtp dentro do diretório do seu Whisper, ficará assim o caminho:
C:\Whisper\dtp
Descompacte o arquivo nessa pasta, são apenas dois arquivos. Cuidado para não jogar a DLL whisper.dll no C:\Whisper ou você quebrará sua instalação.
Clique no ícone do WhisperDesktop.exe e execute-o. Use a interface para escolher o modelo que você quer usar (recomendo começar com o ggml-medium.bin), e clique em OK.

Estou usando o Drive E: mas você se chegou até aqui entendeu o conceito. (Crédito: meiobit)
O modelo será carregado e você será levado para a próxima tela, onde poderá escolher o idioma do arquivo, o arquivo a ser transcrito e o tipo do arquivo de saída, txt, srt, etc.
Aqui, um detalhe interessante da Interface: Quando você selecionar a opção “Translate”, ele sempre irá traduzir para inglês. Caso você deixe a opção não-selecionada, e escolha um idioma, o Whisper irá traduzir o áudio para aquele idioma.
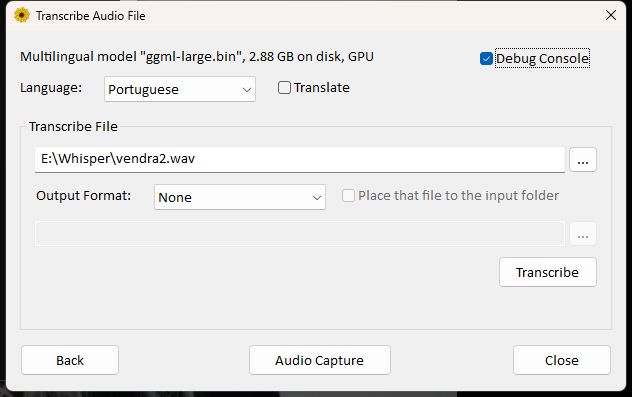
Não clique em Translate (Crédito: Meiobit)
Esta interface gráfica dá menos opções, mas utiliza GPU para o processamento, gerando transcrições em 50% do tempo do Whisper normal.
Ah sim, ela também trabalha com arquivos .MP3, então você não precisa passar pela fase de conversão wololo lá de cima. Assim como com arquivos de vídeo em formato .MP4. Caso sua GPU agüente, é uma excelente alternativa.
Conclusão:
O Whisper é uma ferramenta fundamental para jornalistas, blogueiros, advogados, podcasters, pesquisadores e todo mundo que tenha um acerto de áudio e vídeo e precise consultar e pesquisar esse acervo em texto.
Ao contrário das soluções proprietárias, pagas e “na nuvem”, ele roda 100% local, só depende do seu computador, e assim como o Stable Diffusion, o Whisper não está sujeito aos caprichos moralistas das grandes corporações. Enquanto o Bing Chat é todo cheio de pruridos e não aceita jogar Guerra Total Termonuclear comigo, o Whisper transcreve de boa qualquer barbaridade. Eu testei com o áudio da clássica piada “Morreu Odete!” do Costinha. Infelizmente não dá pra postar a transcrição nesse horário.
Um clássico. (Crédito: MeioBit)
A IA está mudando o mundo, todo dia surge uma novidade que torna nosso trabalho mais fácil, mas se ignorarmos essas novidades, nos tornamos obsoletos. Ficar em dia com as novidades não é mais uma qualidade extra, é uma necessidade.
Felizmente ferramentas como o Whisper tornam quem as usa magicamente eficiente. Só não conte pra ninguém!



