Tutorial: Como instalar e rodar uma IA em seu PC
Ter uma IA rodando em casa não é mais ficção científica, por mais impressionante que pareça, é até simples e vamos explicar como fazer!
![]() Carlos Cardoso 2 anos e meio atrás
Carlos Cardoso 2 anos e meio atrás
IA, Inteligência Artificial, para quem cresceu vendo Guerra nas Estrelas, Star Trek, Perdidos no Espaço era algo meio que inevitável, mas o desenvolvimento glacial do campo, fez com que a IA permanecesse no campo da Ficção Científica, até muito recentemente.

Yes, você pode criar sua própria amiga japinha e conversar com ela (Crédito: Stable Diffusion)
Historicamente a IA era dividida entre IA Fraca e IA Forte. A IA Forte era aquela inatingível, a IA que emularia uma mente inteligente e senciente, como o Tenente-Comandante Data, C3-PO e R2D2 e a maioria dos robôs de ficção científica, HAL-9000 e os programas em Matrix.
Isso nunca aconteceu. 2001 chegou, passou e nenhuma das promessas de computadores inteligentes foi cumprida. A Inteligência Artificial, entretanto, ainda avançava. O campo da IA Fraca evoluiu bastante.
IA Fraca é a IA que tem pretensões mais específicas. Ao invés de tentar simular um ser vivo, uma mente inteira, ela se concentra em problemas menores, como identificar formas e rostos, analisar apólices de seguro, reconhecimento de voz e assistentes como Siri e Alexa, filtros de spam em email, sistemas de recomendação de conteúdo como o da Netflix, e muitas outras atividades.
Nós usamos IA fraca diariamente, sem percebermos, mas o que todos queremos é a IA Forte.
A chegada do ChatGPT pegou de surpresa basicamente todo mundo fora do restrito mundo acadêmico dedicado aos LLMs (Large Language Models), até então chatbots eram pouco mais que truques de salão, específicos como as Alexas da vida.
Por trás do ChatGPT temos uma rede neural com bilhões de neurônios e parâmetros, matrizes com milhares de dimensões, uma maravilha matemática que se não pensa, finge direitinho. E esse é o segredo, ao invés de buscar a AGI, que em português é Inteligência Artificial Geral, a IA Forte.
Eis que os pesquisadores descobriram que o Filósofo Qui-Gon Jinn estava absolutamente certo:
"A capacidade de falar não torna você inteligente."
Linguagem é algo que usamos para expressar pensamento, mas a linguagem em si é algo que pode ser recriado com redes neurais, o que explica tantos animais simples possuírem capacidade de comunicação, como formigas, abelhas e comentaristas de portal.
Em resumo: Linguagem pode existir independente de uma “mente”, e é isso que os LLMs fazem, eles usam redes neurais para aplicar estatística e probabilidade e, depois de pesar bilhões de parâmetros, achar a palavra mais adequada, montando uma frase, passo a passo.
Com modelos suficientemente grandes e complexos, é possível “simular” conversas igualmente complexas. Some a isso uma imensa quantidade de informação catalogada, integrada e inserida na imensa matriz interconectada, e temos uma ferramenta com capacidades incríveis.
Claro, é normal imaginar que essas ferramentas exigem computadores imensos, datacentres inteiros, mas como dito, elas não tentam replicar um cérebro humano, apenas processamento de linguagem, e assim são bem menos exigentes em termos de processamento.
Os modelos Open Source demonstraram que essas exigências são bem mais modestas do que imaginávamos, capazes de rodar mesmo em computadores domésticos.

Sim, é real. Eu tive. (Crédito: MeioBit)
Óbvio que você não vai rodar um modelo de 200 bilhões de parâmetros em um MSX, e o livro que comprei uma vez “Inteligência Artificial no ZX Spectrum: Ensine seu computador a pensar” era por demais otimista, mas dá para fazer muita coisa boa, graças a um conceito chamado “quantização”.
Em essência um modelo, ou checkpoint, é uma matriz de neurônios artificiais com bilhões de parâmetros; basicamente uma imensa lista de números. Esses números podem ser armazenados com diferentes graus de precisão. Números com 32 bits de precisão são bem mais... precisos do que números com 8 bits, por exemplo.
Se um parâmetro tem 32 bits de precisão, ele consegue variar de -2,147,483,648 a 2,147,483,647. Um parâmetro com 8 bits vai variar entre 0 e 255. Ao quantizar um modelo, você converte os valores para formatos menores, como 16 bits, 10, 8 e até 2 bits. Quanto mais quantizado, menos espaço o modelo ocupa, mas ele perde flexibilidade e capacidade.
Peguemos por exemplo este checkpoint, Mixtral-8x7B-v0.1, que segundo o ChatGPT tem 175.12GB. Depois de consolidado via quantização, ele pode ocupar entre 49.62GB ou até apenas 15.64GB.
Isso que nos salvará.
O problema da Censura
Censura, como todo mundo menos a Dona Solange concorda, não é uma coisa legal, mas é compreensível que as empresas como Microsoft, Google, OpenAI não queiram se envolver em imbróglios legais, por isso restringem seus modelos. Você não pode gerar textos ou imagens de cunho sexual, violento, controverso nas ferramentas disponibilizadas por eles.
Em alguns momentos isso chega a ser irritante, eu faço muitas pesquisas sobre Segunda Guerra Mundial e o ChatGPT toda hora fica me avisando que nazismo não é uma coisa legal. Eu sei, sua maldita lata de sardinha enferrujada, eu vi todos os Indiana Jones.
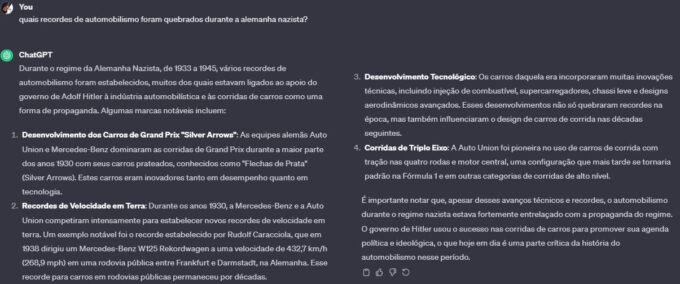
Sempre a lição de moral, mesmo quando responde. (Crédito: ChatGPT)
Muitos usuários usam o ChatGPT para criar cenários para RPG, mas ultimamente não conseguem que qualquer coisa mais violenta que Hello Kitty Island Adventure seja mestrada, isso limita por demais a utilidade da ferramenta.
O problema da Privacidade
Muita gente tem receito de fornecer dados sigilosos para o ChatGPT, Bing, Bard e outros. É uma preocupação válida? Provavelmente, depende se você confia cegamente em grandes corporações ou não. Um modelo local resolveria esse e outros problemas.
Como rodar um LLM localmente?
A forma mais completa é com o Text Generation WebUI, mas é uma aplicação extremamente instável, que exige conhecimentos razoáveis de Python, Computação, linha de comando, instalação de dependências e todos os paranauês de um desenvolvedor das antigas. Não é para amadores.
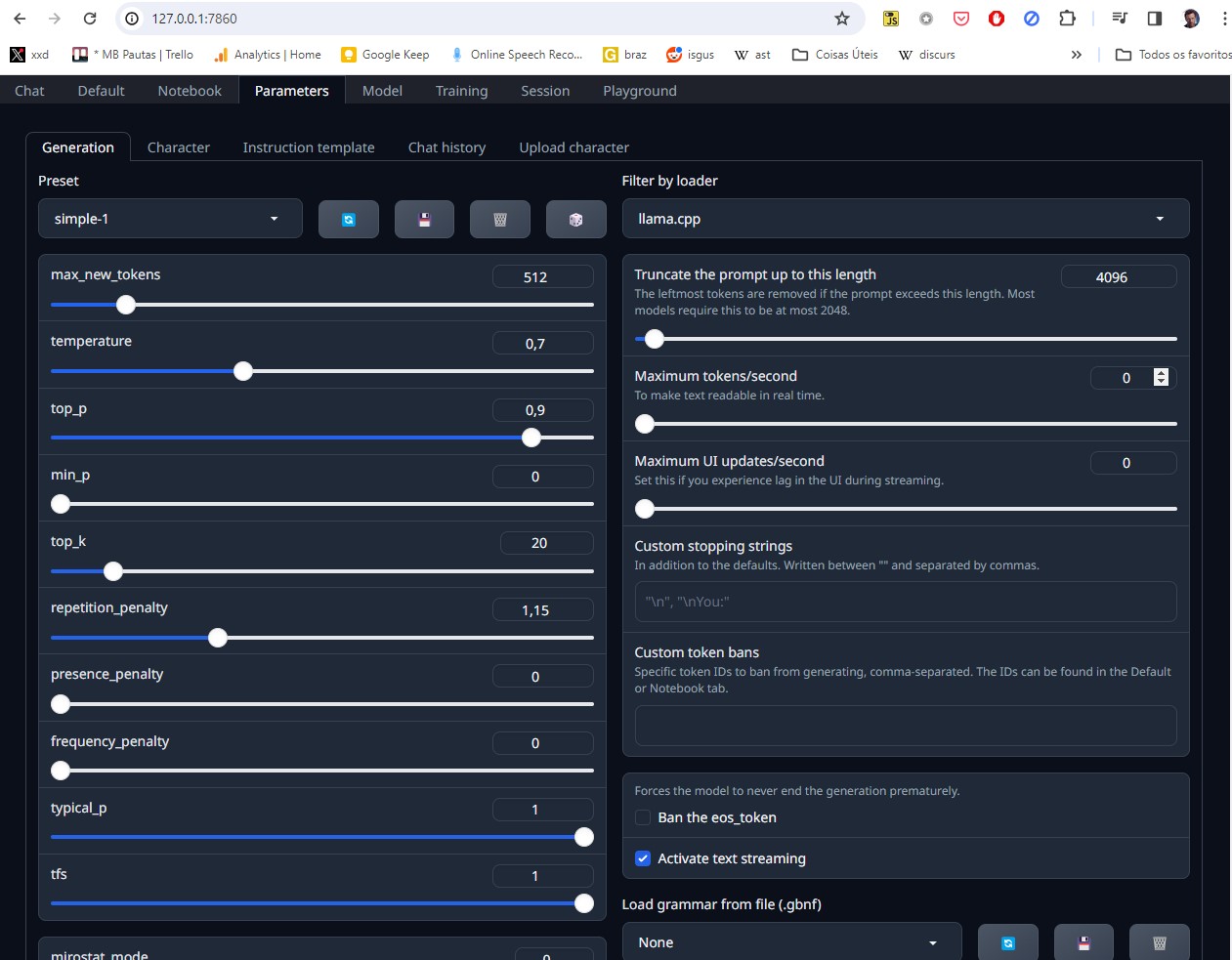
Ele é bem poderoso, mas bem mais complexo. (Crédito: MeioBit)
O grande problema é que existem diversos ambientes possíveis para rodar LLMs, dependendo da sua CPU e principalmente da sua GPU. A maioria das soluções roda em Nvidia, o uso de GPUs AMD é mais complicado e trabalhoso.
Em termos de recomendação de Hardware, eu sugiro como requisito mínimo um processador equivalente a um Ryzen 5 5600, uma placa de vídeo com pelo menos 6 (preferencialmente 8) GBs de VRAM, e pelo menos 16GB de RAM no sistema.
Em termos de software, uma boa solução “universal” é o Koboldcpp, uma aplicação Open Source com versões para Linux e Windows que oculta boa parte da complicação. A instalação é tão simples que não tem instalação, mas vamos ser organizados.
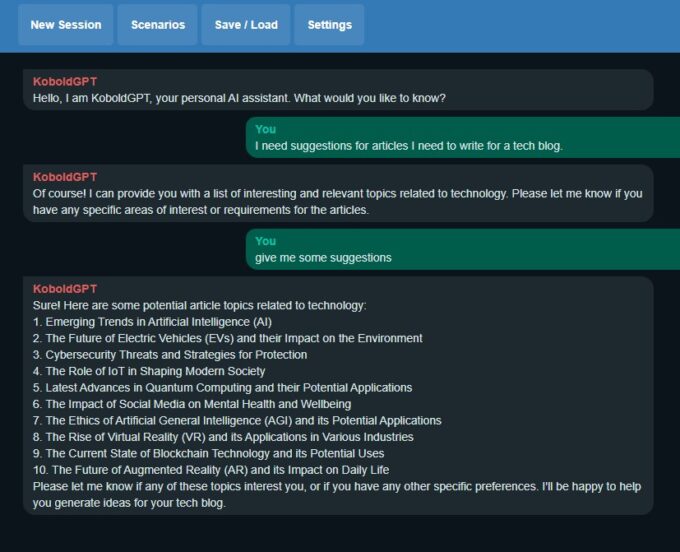
Koboldcpp ajudando blogueiros preguiçosos (Crédito: MeioBit)
Vamos Instalar o Kobold!
Primeiro, crie uma pasta chamada TEXTGEN na raiz do seu disco C:
Agora vá no repositório do Kobold no GitHub e baixe a última versão. Desça até o fundo da página e baixe o arquivo koboldcpp.exe. Mova-o para a pasta C:\TEXTGEN. Agora... não faça nada. Precisamos de um checkpoint. Onde conseguir um? No Huggingface, claro.
Mais precisamente na página de um sujeito chamado The Bloke, ele se especializou em quantizar modelos assim que são lançados, ele faz um trabalho fundamental para a comunidade.
Além de quantizar os modelos, ele os converte para o formato GGUF (Georgie Jurgenov's Unified File format), uma versão compacta e versátil, compatível com CPUs E GPUs simultaneamente.
Vamos para a página com as opções de download do modelo Llama-2, com 7 bilhões de parâmetros. Há diversas opções, listando a perda de qualidade, o tamanho do arquivo e o mínimo de RAM necessária para rodar o modelo.
Eu recomendo que inicialmente você baixe o arquivo llama-2-7b-chat.Q4_K_M.gguf para o diretório C:\TEXTGEN
Terminado o download, clique no executável KOBOLDCPP.EXE no diretório C:\TEXTGEN. Você provavelmente será interrompido por uma mensagem meio assustadora do Windows. Cliquem em Mais Informações, em depois em “Executar mesmo assim”. Não se preocupe, é alarme falso, nada de ruim vai acontecer com seu computador.
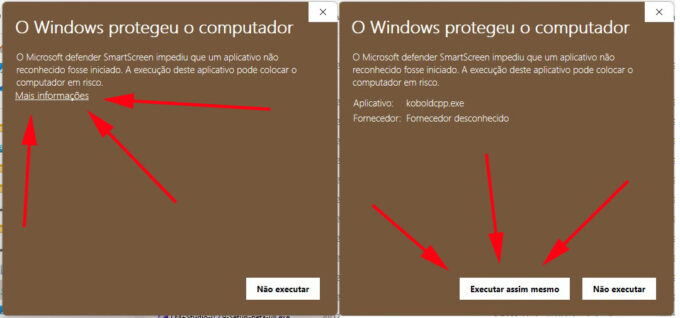
Pode confiar. (Crédito: MeioBit)
Execute o Kobold. Uma janela de terminal irá se abrir, seguida de uma interface vinda direta dos Anos 90:
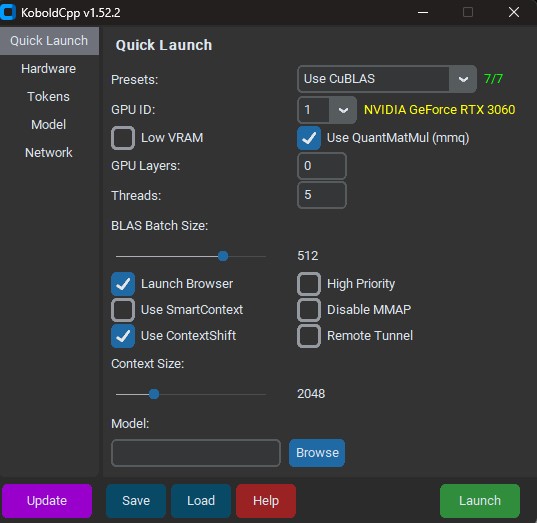
Feio bagarai, eu sei (Crédito: MeioBit)
Tudo que precisamos está nesta primeira tela, e na primeira opção, Presets, temos a escolha mais importante: Como os dados serão processados. Dependendo das características de seu sistema, algumas opções não estarão disponíveis.
1 – CuBLAS o CU no caso vem de CUDA, essa opção é específica para GPUs da Nvidia. BLAS é um acrônimo de Basic Linear Algebra Subprograms, um conjunto de funções que transfere para a GPU operações como multiplicação de matrizes e outras contas esotéricas de álgebra linear. CuBLAS é o que você deve escolher se tem uma GPU minimamente decente, de uma 1050 pra cima.
2 – ClBlast é a opção genérica, funciona em qualquer GPU, mas não é tão eficiente quanto a CuBLAS, mas ao menos vai fazer sua AMD servir pra alguma coisa.
3 – OpenBLAS usa uma biblioteca BLAS rodando 100% em CPU. É a opção para quem não tem uma GPU.
Note que mesmo que você use CuBLAS, sua CPU vai ser usada também, se o modelo carregado for maior do que a VRAM disponível.
Sua GPU deverá aparecer logo abaixo do menu de presets. Há uma opção para escolher, caso você tenha mais de uma GPU na mesma máquina.
Ignore a opção Low VRAM, ela só existe para fins históricos.
A opção GPU Layers é preenchida automaticamente quando você carrega o modelo. Ela indica quantas camadas do modelo serão mantidas na GPU, acelerando o processamento. Camadas demais geram estouro de memória, mas no geral o valor automático está correto.
Abaixo vem a opção de threads. O recomendado pela documentação do Kobold é manter como threads o mesmo número de núcleos de sua CPU. Minha recomendação é que você use tudo que tiver disponível. Tem 6 núcleos? Meta 12 threads.
Ignore os outros valores e desça até Context Size: Aqui é determinado em tokens a “memória” da sua IA. O valor de 2048 é suficiente para usos simples, consultas isoladas e bate-papos. Histórias, roleplaying e usos mais elaborados exigem um contexto maior. Não se empolgue muito, a maioria dos modelos são treinados para contextos entre 2048 e 4096 tokens, e aumentar o contexto come MUITA memória e C(G)PU.
NOTA: Bard, explique o que são tokens.
“No contexto de LLMs (Large Language Models), um token é uma unidade básica de texto que um modelo de linguagem pode entender e processar. Um token pode ser tão pequeno quanto um único caractere ou tão longo quanto uma palavra. Em alguns modelos sofisticados, os tokens podem até representar frases inteiras.
Basicamente, tokens são as peças de texto que os modelos de linguagem lêem e analisam. Eles servem como os dados de entrada primários que esses modelos usam para realizar tarefas que vão desde a classificação de texto até a geração de linguagem.”
Agora a parte mais importante: O modelo. Clique em Browse e selecione o arquivo llama-2-7b-chat.Q4_K_M.gguf, no diretório C:\TEXTGEN.
Clique em Launch. O modelo será carregado e seu navegador abrirá em uma página assim:
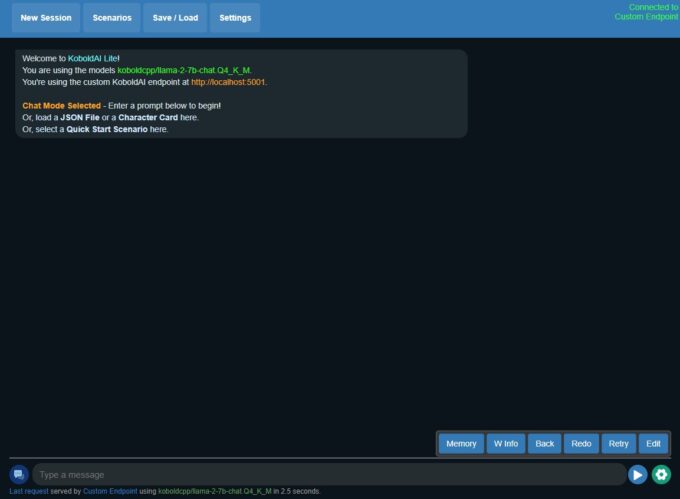
Página inicial do Koboldcpp (Crédito: MeioBit)
Ou seja, você já está pronto para conversar.
Mesmo os modelos pequenos entendem português, mas costumam responder somente em inglês. É meio aleatório, às vezes a conversa muda sozinha para português, mas se você pedir ele sempre traduz a última resposta.
Já Está Funcionando?
Exato, assim, simples, sem mais nenhuma configuração, você pode começar a conversar com a IA, The End, fim do tutorial.
OK, nem tanto. Clique em Settings, no alto da tela. Primeiro, não toque na aba Advanced, coisas ruins acontecem por lá. Fiquemos na Basic, onde apenas algumas configurações nos interessam.
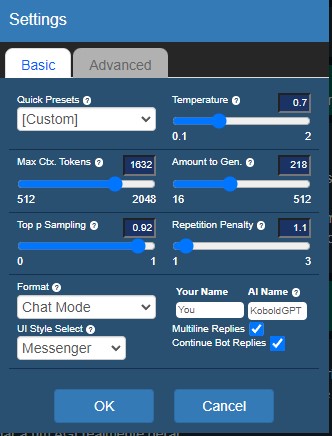
Settings. (Crédito: MeioBit)
A primeira, é a Max Ctx. Tokens, que determina o tamanho da “memória”, as informações enviadas para a IA a cada consulta. O software cria um resumo das mensagens anteriores e o envia, simulando memória de curto prazo. Isso consome memória (real, VRAM e RAM). No dia-a-dia, você pode manter o valor padrão, ou até subir para 2048. Só vá para 4096 ou acima, se estiver usando a IA para escrever histórias.
Amount to Gen. Essa opção determina quantos tokens serão gerados na resposta da IA. O valor default é muito baixo, coloque uns 250. Do contrário você terá mensagens muito sucintas. Valores muito alto, entretanto, geram respostas mais verborrágicas.
Format
Aqui escolhemos o (duh!) formato da interação com a IA. São quatro opções:
Story – É o ideal para histórias, você começa a historinha, a IA continua. Você pode corrigir, alterar e direcionar o enredo.
Chat Mode – Modo para conversas com a IA.
Adventure – Para brincar em mundos imaginários, sagas em terras distantes, o que os jovens chamam de RPG
Instruct – É o equivalente ao ChatGPT, onde você comanda e ele obedece.
Mas não mexa nessas opções.
UI Style Select
Esta opção define o formato da interface, que pode ser clássica, Messenger ou Aesthetic. Essa última permite avatares e outras customizações, clicando na engrenagem ao lado da opção.
Aqui os formatos Classic, Messenger e Aesthetic:
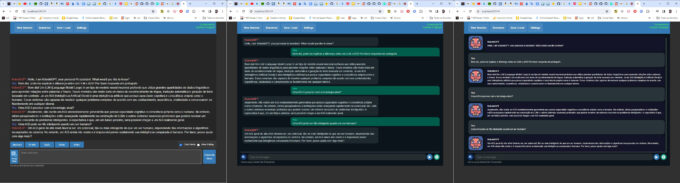
Os três formatos principais do Koboldcpp (Crédito: MeioBit)
CENÁRIOS:
No alto da tela temos quatro opções: New Session, Scenarios, Save / Load e Settings. Settings já vimos como funciona, Save/Load é autoexplicativo, New Session cria uma conversa nova do zero. O que nos interessa aqui é Scenarios. Ela permite iniciar vários tipos de sessões, mas a mais familiar aqui é a KoboldGPT Chat, que cria uma interação semelhante ao ChatGPT. Selecione-a.
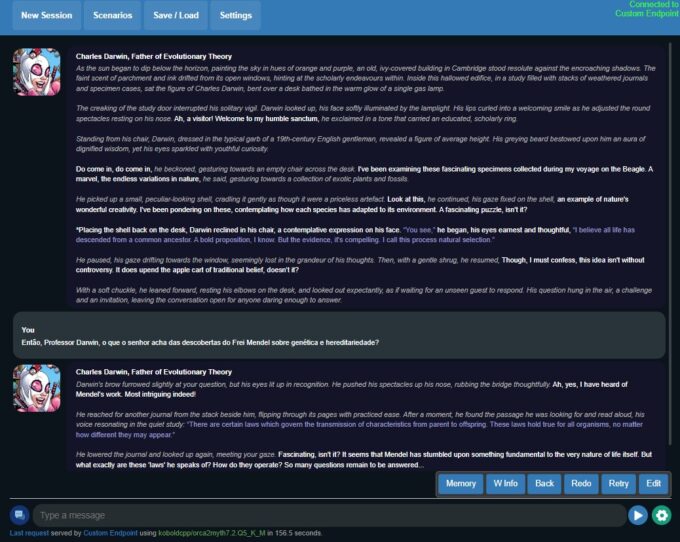
Aqui eu converso com uma versão virtual de Charles Darwin. Não repare no avatar da Gwenpool. (Crédito: Meiobit)
Agora, no canto inferior direito da tela, clique em Memory. Essa configuração é que define as características da IA, descritas em um formato de texto simples, em geral JSON.
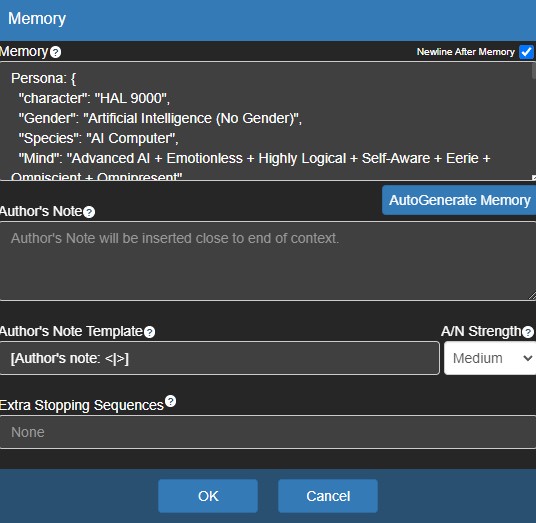
Descrição de um personagem para a IA interpretar (Crédito: MeioBit)
Quando iniciamos uma nova sessão, há a opção de carregar um PNG de personagem ou o .JSON. Os PNGs são uma excelente e compacta forma de armazenar personagens, os dados são guardados em metadados. Arquivos .json também são bem úteis, mas o PNG tem a vantagem de já virar avatar automaticamente.

Se o WordPress colaborar, arrastar e soltar essa Gwenpool no Koboldcpp será o suficiente para ativá-la. (Crédito: MeioBit)
Você pode achar personagens para baixar no botprompts.net, há alguns até em português. Em um futuro artigo ensinarei como criar seus próprios personagens para interagir no chat.
Grandes Poderes, Grandes Responsabilidades
Modelos como Mistral, Mixtral, Mythomax, Dolphin e outros não são censurados, o que significa que você pode perguntar qualquer coisa, pedir todo tipo de história, mas cuidado. Você é responsável pelo que sua imaginação sugerir, não a IA.
Não que isso seja horrível horrível... (Crédito: MeioBit)
Limitações:
Os modelos menores são menos inteligentes e versáteis, e têm mais dificuldade em falar português. Internamente eles traduzem tudo para inglês e isso fica bem visível, às vezes eles se confundem de forma hilária. Eu recomendo que você use a IA para treinar seu inglês, se não entender algo, peça e ela traduzirá ou explicará.
Menções honrosas:
Cliente offline como o Koboldcpp, faz download direto dos modelos, bem organizado.
Outro cliente off, mais complexo que os anteriores, mas com versões Mac, Windows e Linux.
[EDIT] Velocidade
O povo está perguntando sobre velocidade. Aqui o TextGen WebUI rodando localmente na minha máquina, em tempo real. É basicamente a mesma velocidade do Koboldcpp.



